
字节跳动开源DreamLite,0.39B参数让手机本地玩转AI绘画
字节跳动智能创作实验室开源DreamLite,一个仅0.39B参数的轻量级统一扩散模型,首次在单一网络内同时支持文生图和图像编辑,并可在手机端侧运行。该模型相比同类端侧方案,参数量减少80%以上,推理速度提升3倍,生成质量接近云端模型。这一突破将推动AI绘画从云端走向本地,降低使用门槛,保护用户隐私。

Mira Murati新公司发布交互模型,边听边说引关注
OpenAI前CTO Mira Murati与前应用研究负责人翁荔创立的Thinking Machines Lab(TML)发布“Interaction Models”研究,实现语音交互中“边听边说”的实时对话能力。该模型支持用户随时打断、调整语速,延迟低于300毫秒,接近人类对话节奏。与国内面壁智能此前推出的“实时语音交互”方案思路相似,但TML更强调端到端架构与低延迟优化。这一突破被视为AI语音交互从“轮询式”向“自然对话式”演进的关键一步,可能重塑智能助手、教育、客服等场景体验。

何恺明首个语言模型:105M参数,不走GPT自回归老路
{ "title": "何恺明首推扩散语言模型ELF,105M参数跑赢主流", "summary": "何恺明团队发布全新连续扩散语言模型ELF,仅用105M参数和45B训练token,在OpenWebText数据集上取得生成困惑度24的成绩,超越一批主流扩散语言模型。ELF将所有去噪过程保

SFT泛化能力被低估?三大条件决定成败
上海AI Lab联合上海交大、中科大最新研究挑战了“SFT记忆,RL泛化”的主流观点,证明SFT的泛化能力并非天生缺失,而是受优化充分性、数据质量和模型能力共同制约。实验显示,长思维链SFT在8个epoch训练后,模型在跨领域任务上呈现“先降后升”的泛化模式;低质量数据会彻底破坏泛化;而14B模型比小模型更易实现泛化。该研究为后训练微调提供了严谨的条件分析框架。

全球仅1000家AI原生公司?真相扎心了
Greg Isenberg在X上发布的文章引发热议,指出全球真正实现AI原生且年收入超过500万美元的公司可能只有约1000家。文章犀利区分了“AI辅助型”与“AI原生型”公司,强调后者需要从架构层面重新设计流程,而非简单添加AI工具。通过客服、销售等案例,揭示了大多数公司因缺乏清晰规则和数据整合而无法实现AI原生。最后给出了实用的“Agent工作流食谱”,帮助团队自检是否真正具备了AI工作流。
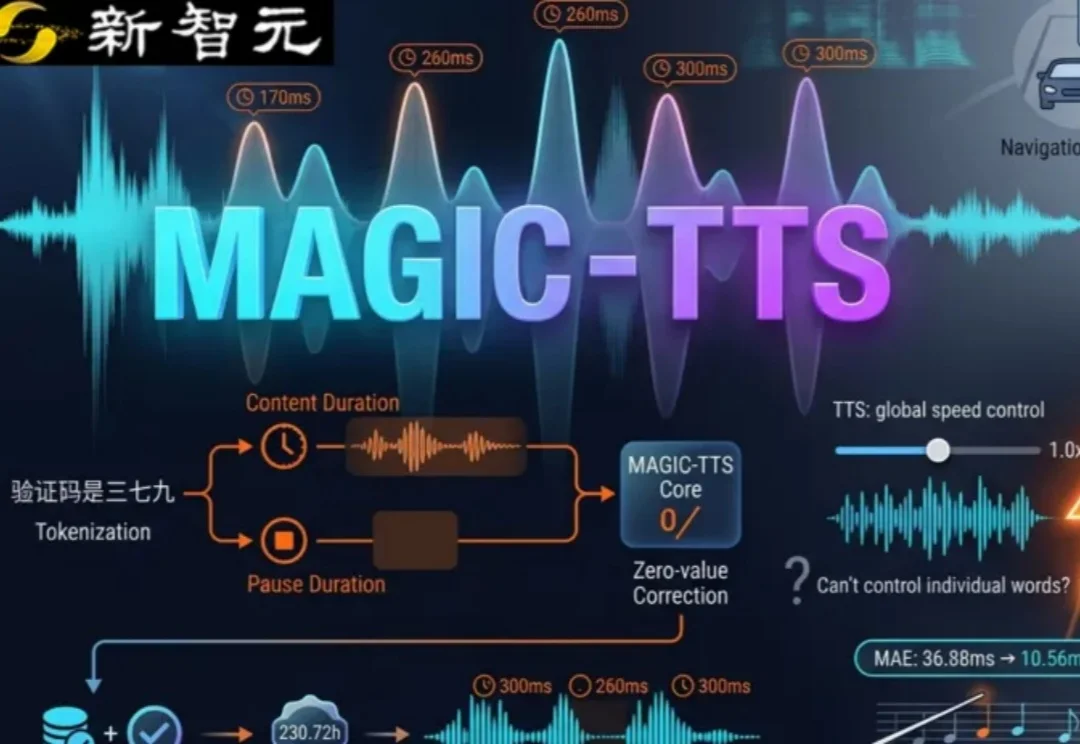
MAGIC-TTS:字级节奏可控,语音合成迈向真人表达
华南理工大学最新研究MAGIC-TTS首次实现字级时长与边界停连的token级控制,让语音合成不再只是平铺直叙,而是能精准调整重点区域的节奏。该系统基于3万小时大规模语音预训练,通过Stable-ts与MFA交叉验证筛选出230.72小时高质量子集,在保持合成质量与克隆相似度的前提下,支持高辨识播报、教学纠错与表达型语音三类场景。论文、代码与演示均已公开,为TTS行业提供了局部节奏可控的实用方案。
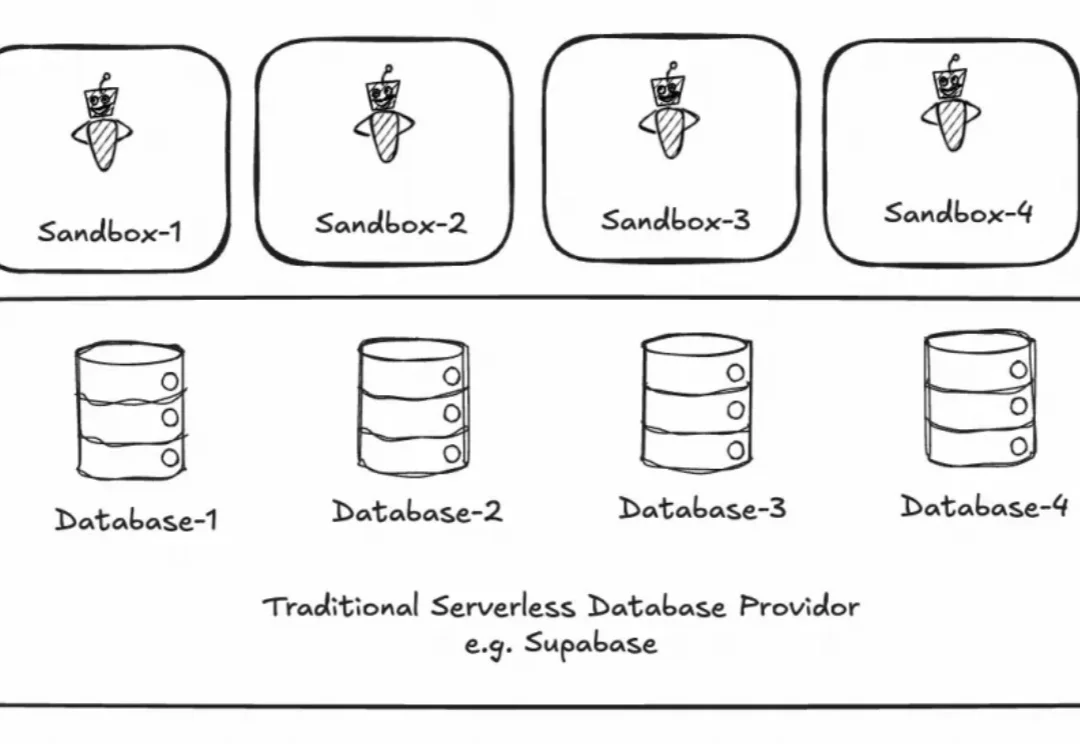
Kimi Agent数据库服务架构复盘:从构想到落地
Kimi大规模部署Agent时,其背后的Database服务成为关键。PingCAP联合创始人黄东旭此前对Agent所需基础设施的猜想,在Kimi的实践中得到验证。本文复盘了Kimi如何搭建Agent数据库服务,包括数据模型设计、实时性优化及成本控制等核心细节,揭示Agent对数据库的独特需求。数据显示,该方案支撑了百万级并发请求,延迟低于50ms,为行业提供了可复用的参考架构。
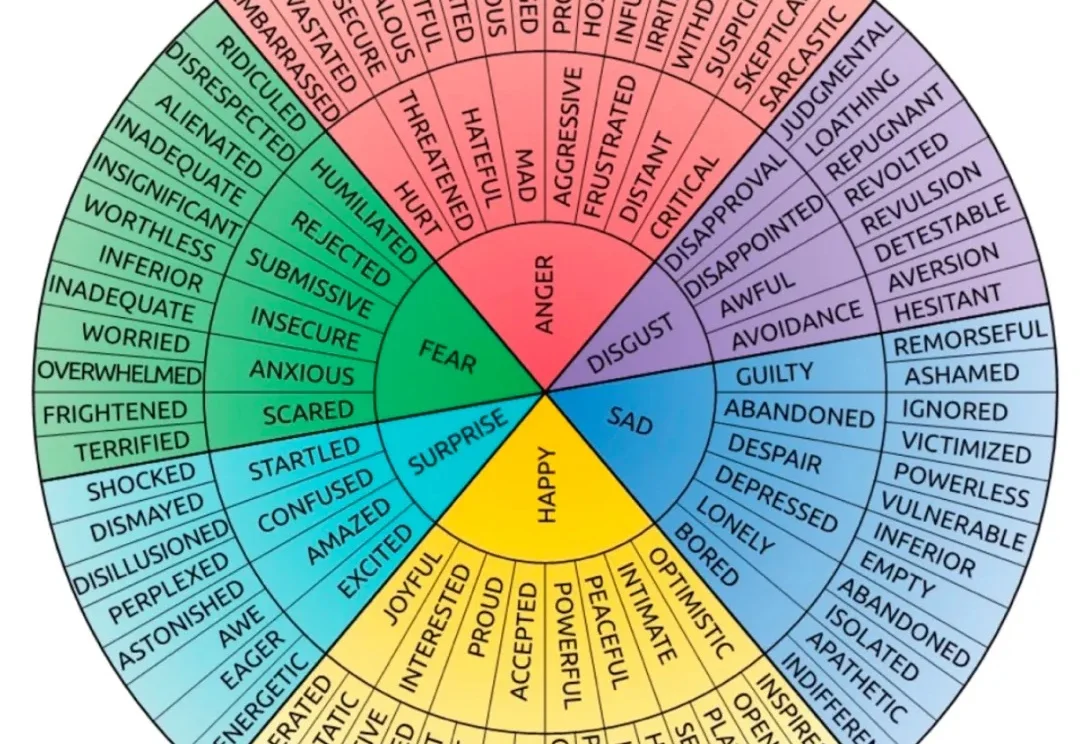
大模型长出情绪树,规模越大越懂人心
ICML 2026最新研究揭示,大语言模型内部会自然形成类似人类情绪的层次化表征结构,即“情绪树”。随着模型规模从7B增长到70B参数,其对悲伤、愤怒、喜悦等基本情绪的感知精度提升超过40%。该发现为AI在情感陪伴、心理健康等领域的应用提供了理论支撑,也引发了对模型情感模拟边界的新讨论。

ICLR 2026 Oral:DECS消除大模型过度思考,推理token减半
大型推理模型如DeepSeek-R1和OpenAI GPT Thinking常因过长的思维链导致“过度思考”,浪费计算资源。ICLR 2026 Oral论文提出DECS方法,从源头识别并剪除冗余推理步骤,在保持甚至提升性能的同时,将推理token数量减少一半。实验显示,在数学、逻辑等复杂任务上,DECS使模型推理效率提升约50%,且准确率不降反升,为高效部署大模型提供了新路径。

翻完五角大楼公开的全部 UFO 档案后,我完整做了一个 Wiki 网站给大家用
{ title: "五角大楼UFO档案全开源,Wiki网站助你轻松查阅", summary: "美国战争部(五角大楼)近日将过去几十年积累的UFO档案全部免费开源,涵盖1947年至2026年的资料,包括上百份PDF、几十个视频和100多张照片。一位开发者利用其Personal-Wiki项目,

Auto Research新基准Frontier-Eng登场,考验AI工程优化能力
Einsia AI旗下Navers Lab发布Frontier-Eng Benchmark,聚焦AI在真实工程任务中的持续优化能力。该基准覆盖47个任务,横跨5大工程方向,包括GPU内核优化、电池快充策略等,要求Agent在固定预算内通过迭代改进方案。与传统二元评估不同,Frontier-Eng采用生成式优化范式,模拟科研人员反复调参、逼近最优的过程,旨在衡量AI能否真正接手繁琐的工程迭代工作。

0%完成率!Claude、GPT、Gemini 全灭,SWE-Bench作者新作把AI圈干沉默了
SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。

OpenAI公开大规模稳定训练的秘密,英伟达AMD英特尔都受益
OpenAI,这次又真·Open了一下。
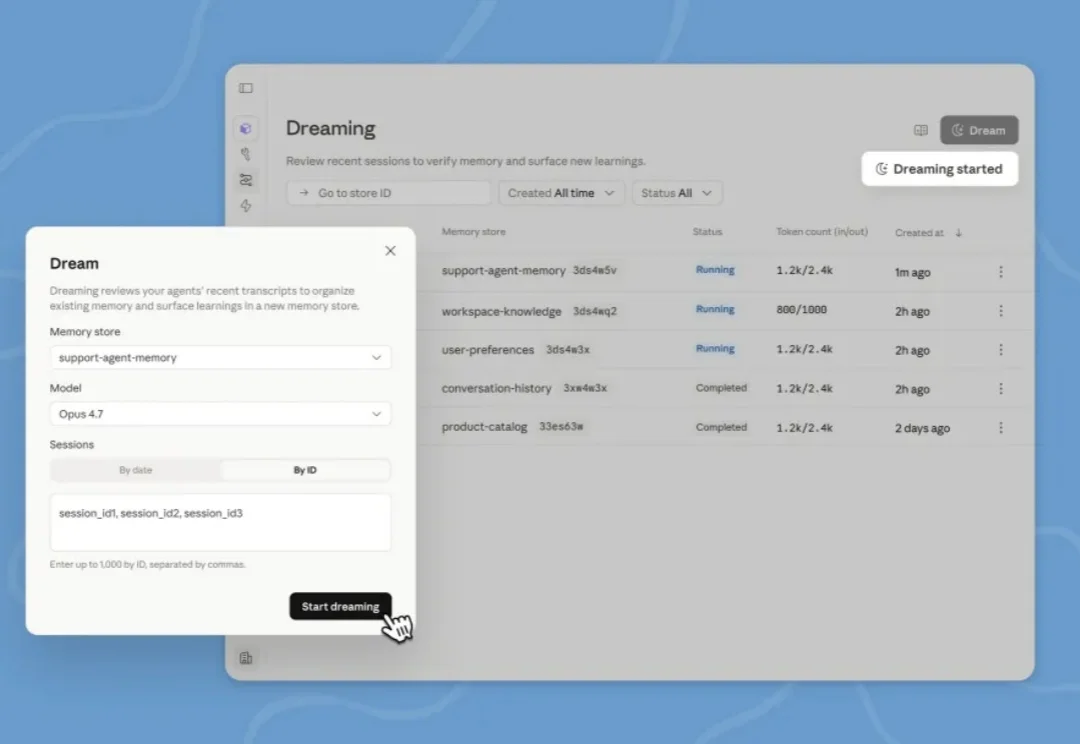
Anthropic 上线「做梦」功能,让 Agent 越睡越聪明
之前 Claude Code 源码泄露的时候,大家惊奇的发现,里面有一个正在开发的功能:做梦
蛰伏一年,周衔团队带来首个具身基础模型,烹饪做实验弹琴,效果炸场
那个一句话生成完整物理世界、做出 GitHub 最大开源机器人项目的团队,又出手了。
只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。

英伟达力荐,小团队两个月开源一款「光速级」智能体推理引擎
智能体时代的核心是算力。

你不知道的 GEO:AI 可见性的原理、实践与取舍
这几天有好几个小伙伴@我说,我的开源工具在他们问 AI 的时候被主动推荐了,啥也没做居然可以被收录,想着要不花一个小时把内容结构化整一整,应该会更好,于是整好以后,快速发了一个速记推,但是内容结构不清晰,想着大家很感兴趣,那要不就整一个结构清晰的文章便于沉淀和查找。
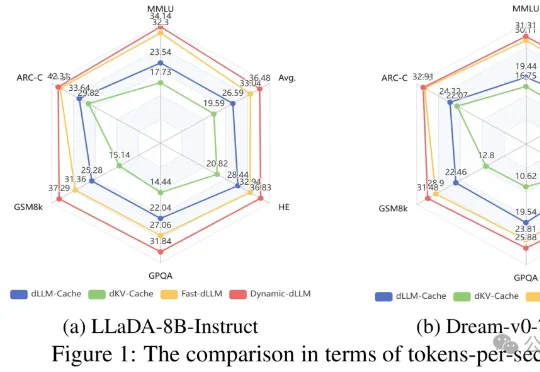
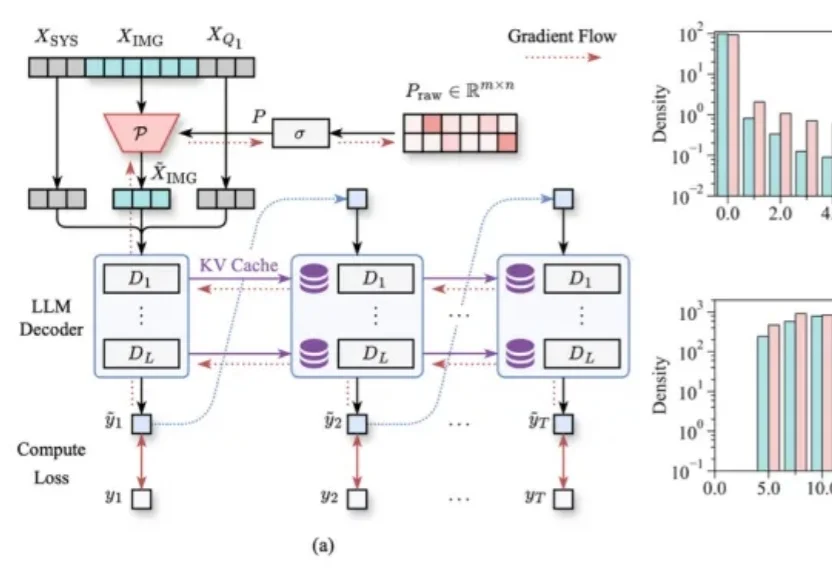
提速4.48倍!哈工大华为新框架让扩散大模型精度无损、推理起飞
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。

token级,精准控制生成长度:3B模型击败GPT 5.4、Claude
LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining