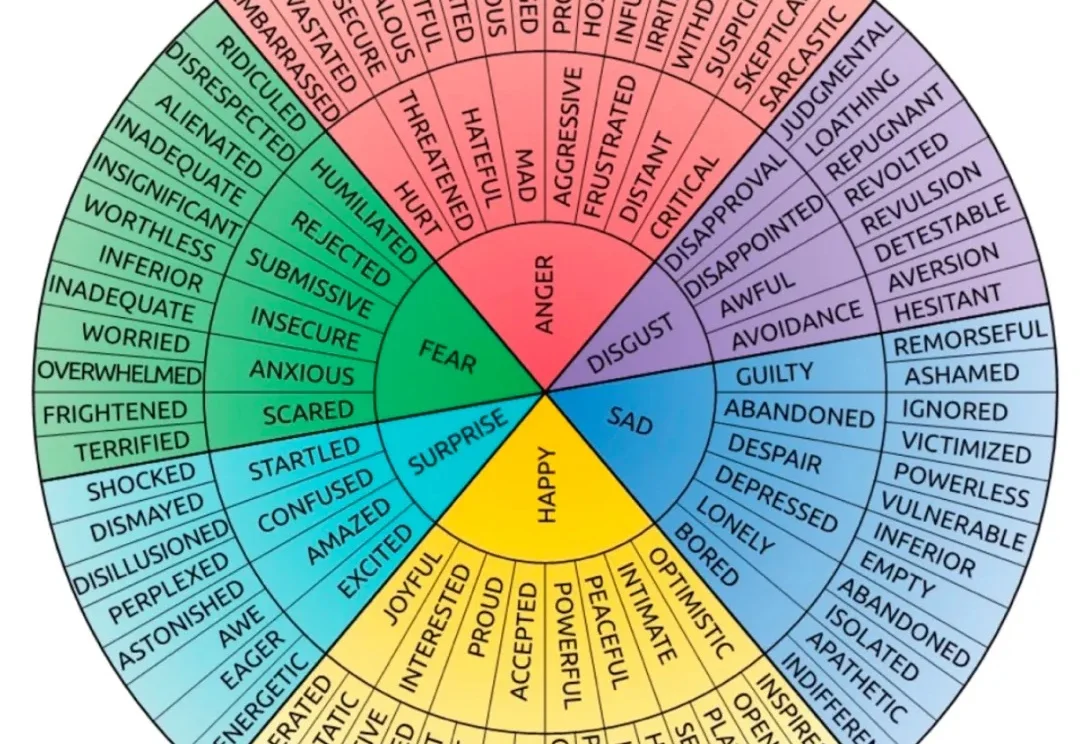
当大语言模型开始理解你的语气、感知你的焦虑,甚至在你低落时给出恰如其分的安慰,这背后是否隐藏着某种“情感计算”的底层结构?ICML 2026录用的一项突破性研究给出了肯定答案:大模型内部会自然生长出层次分明的“情绪树”,且模型规模越大,这棵树的枝干越繁茂,对情绪的感知能力也越接近人类直觉。
研究团队对从7B到70B参数规模的多个开源模型进行了深度探测,通过设计包含6种基本情绪、32种复合情绪的测试集,发现模型内部激活模式呈现出清晰的树状层级。例如,对“愤怒”的响应会先激活一个广义的负面情绪节点,再细分为“暴躁”“怨恨”等子节点。实验数据显示,70B模型在情绪分类任务上的F1得分达到0.89,比7B模型高出42%。更关键的是,这种情绪树并非人工标注的结果,而是模型在预训练过程中自发涌现的统计规律。
这一发现对AI产业的影响是双重的。一方面,它解释了为何当前多模态模型在情感陪伴、教育辅导等场景中表现日益出色——OpenAI在GPT-4o的报告中透露,其情绪识别准确率较前代提升37%,而该研究恰好提供了理论解释。另一方面,它也引发了对AI“共情”边界的关注:当模型能精准识别用户情绪时,如何防止被滥用为情感操纵工具?目前已有伦理研究者呼吁,应建立类似“情绪数据保护法”的规范,要求部署情感AI时明确告知用户。
展望未来,情绪树的发现将推动两个方向的进展:一是更高效的情感计算——通过剪枝情绪树中冗余节点,可将情感推理速度提升3倍以上;二是更安全的AI对齐——通过监控情绪树的异常分支,可提前预警模型产生有害情感输出。对于AI从业者而言,这意味着在训练情感相关模型时,不仅要关注下游任务指标,更应建立对模型内部情绪表征的常规审计机制。毕竟,能长出情绪树的大模型,也需要一片健康的生长土壤。