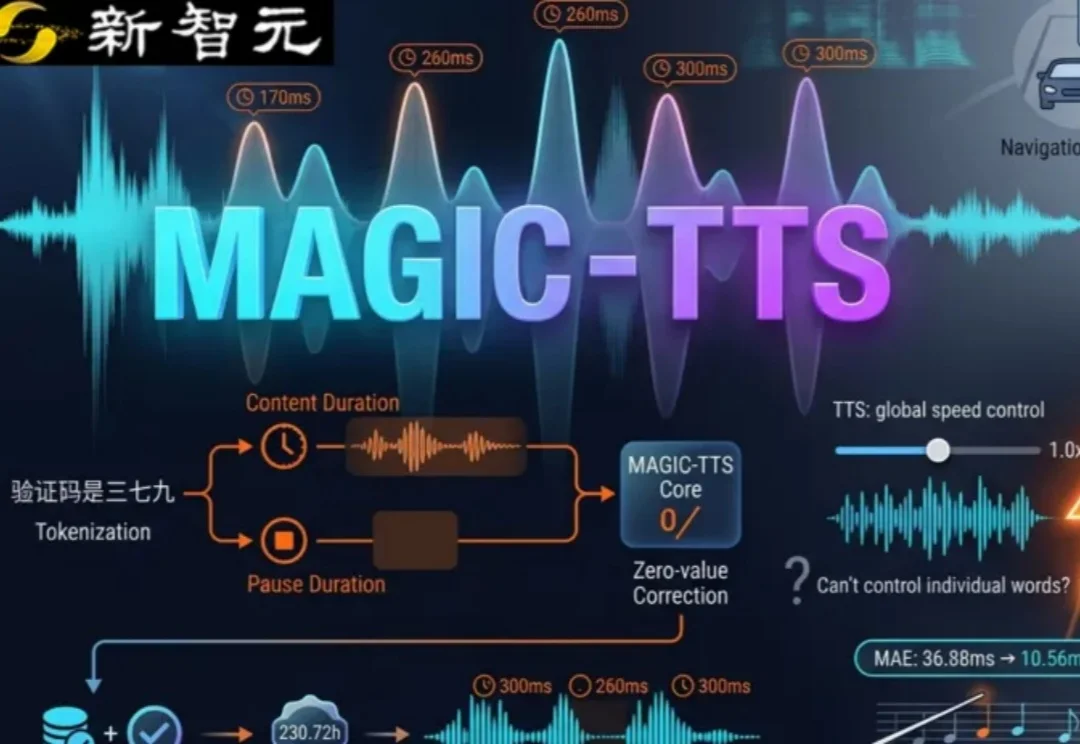
语音合成技术近年进步显著,流畅朗读一段文字已不再是难题。但真正的挑战在于:如何让机器在该慢的时候慢下来,该停顿的时候停顿,该强调的重点能自然突出。华南理工大学最新提出的MAGIC-TTS系统,首次将字级时长与边界停连控制提升到token级别,实现了局部节奏精准可控的语音生成能力。这项研究的意义在于,它让TTS从单纯的发声工具,开始向会安排句子内部节奏的表达者进化,同时不牺牲合成质量与语音克隆的相似度。论文、代码与演示均已公开,为行业提供了可落地的技术路径。MAGIC-TTS的核心突破在于将一句话中的两种时间因素拆解开来:每个词本身的展开时长,以及每个词之后的边界停顿。过去,多数系统只能实现整体变速或套用全局风格标签,无法只调整重点区域。而MAGIC-TTS通过精确分配局部时间,让模型在关键位置做出差异化处理。例如在验证码播报中,系统刻意拉开数字分组的停顿,并放慢数字本身,使用户先听清分组再听清每个数字,而非整体降速。类似地,在地铁播报场景中,系统将站点出现前的停连做得更明显,同时加重站名发音,节奏准确性比音色更像真人更有价值。技术实现上,MAGIC-TTS首先利用Stable-ts在3万小时大规模语音数据上构造token级时序标签进行持续预训练,随后结合Stable-ts与MFA(蒙特利尔强制对齐工具)进行交叉验证,筛除不可靠样本,最终保留230.72小时的高置信度子集。这一工程步骤确保了训练时每个token起止位置的稳定性,从而让推理时的局部拉长或停顿控制变得可靠。实验表明,该系统在保持合成自然度与克隆相似度的前提下,能够稳定实现字级时长调整与边界停连控制,解决了行业长期面临的局部控制与全局质量难以兼得的痛点。这项能力对三类任务影响最为直接。一是高辨识播报,如验证码、订单号、药品名等场景,通过节奏调整提升听辨准确率;二是教学纠错,如英文近音词区分,通过缩短前词、拉长后词并加入短暂停顿,让语义差异更清晰;三是表达型语音,如在句尾关键词前留白并拉长,增强叙事张力。过去这些处理依赖真人配音或后期剪辑,现在TTS开始向这个方向迈进。随着局部节奏控制技术的成熟,语音合成将从平铺直叙的朗读器,进化为能根据内容与场景主动安排表达节奏的智能系统,为导航、教育、有声书等领域带来更自然、更精准的交互体验。
MAGIC-TTS:字级节奏可控,语音合成迈向真人表达
AITNT
2026-05-13 10:00
31
15