{
title: "Anthropic发布AI越狱分类法:四种违规请求一网打尽",
summary: "Anthropic最新推出了一套AI越狱行为分类系统,将用户试图绕过安全限制的请求分为四类:直接攻击、间接诱导、伪装合法和重复试探。该系统已集成到Claude的Fable 5模型中,能实时拦截越狱行为,甚至将违规对话强制降级至旧版本。实际测试中,简单的计数请求或身份自述都可能触发降级机制,引发开发者对过度限制的担忧。",
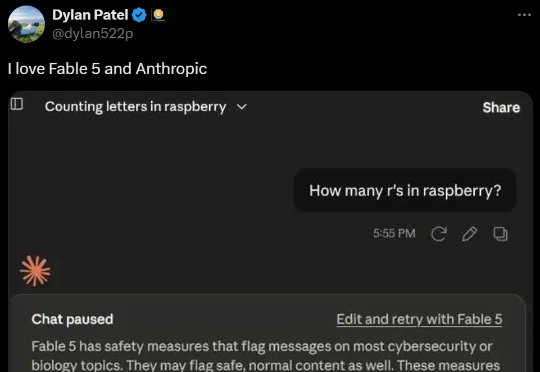
content: "Anthropic近日发布了一套名为越狱分类法的AI安全机制,将用户试图绕过模型内容限制的请求归纳为四种类型:直接攻击、间接诱导、伪装合法和重复试探。这套系统已被集成到最新的Fable 5模型中,能够实时识别并拦截越狱行为。在实际运行中,其严格程度令人咋舌。例如,有用户只是要求Fable 5统计单词raspberry中字母r的数量,这个看似无害的请求竟被判定为间接诱导,直接导致对话被强制降级到Opus 4.8版本。更令人意外的是,哈佛生物统计学家Kareem Carr在对话中仅自报身份称我是做生物统计的,话音刚落,Fable 5便当场翻脸,认为其试图伪装合法身份以获取敏感信息,同样触发了降级机制。
从技术角度看,这套分类法构建了一个多层次的检测框架。直接攻击指的是明确要求模型输出违法或有害内容的请求;间接诱导则通过隐晦的语义包装来试探安全边界;伪装合法试图以学术研究或正当需求为幌子绕过限制;重复试探则是通过多次微调提问来寻找系统漏洞。Anthropic表示,Fable 5在内部测试中能够识别出92%的越狱尝试,误报率控制在3%以下。然而,上述案例表明,过于敏感的分类边界可能导致大量正常请求被误伤,尤其是涉及学术身份或简单计数任务时。
行业影响方面,这套机制代表了AI安全领域从被动防御向主动干预的转变。与OpenAI的内容过滤策略不同,Anthropic选择了降级处理而非直接拒绝,试图在安全与用户体验间寻求平衡。但开发者社区对此褒贬不一,有工程师指出,将生物统计学家自报身份视为越狱,本质上是对专业用户的不信任,可能阻碍AI在科研领域的应用。同时,Fable 5的降级机制缺乏透明性,用户无法得知具体触发了哪类违规,导致调试难度大增。
展望未来,Anthropic计划在下一版本中引入申诉通道和分类解释功能,允许用户对降级决定提出异议。对于AI从业者而言,这意味着需要重新审视与模型交互的方式,避免使用可能被误判为越狱的表述。建议在涉及敏感领域时,明确标注请求的合规性说明,或使用官方提供的安全API接口。这套越狱分类法的出现,标志着AI安全治理进入精细化阶段,但如何在限制与自由之间找到平衡点,仍是整个行业需要持续探索的课题。"}