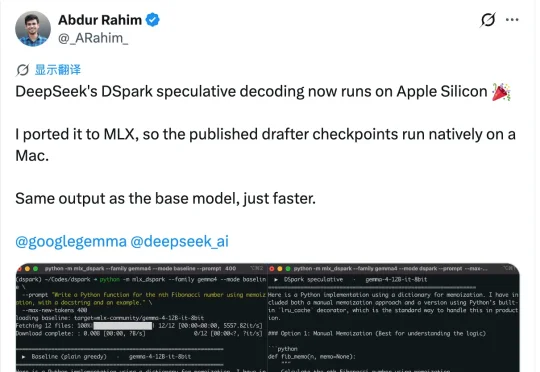
开源AI技术DSpark刚刚发布一周,就被开发者迅速搬进了苹果电脑。这个名为mlx-dspark的移植版本,专门针对苹果芯片进行了优化,让本地大模型的生成速度大幅提升。根据测试数据,Gemma-4 12B模型的生成速度提升了1.6倍,而Qwen3-4B模型也获得了1.4倍的加速,最高增幅达到60%。这意味着Mac用户现在可以更流畅地运行这些模型,而无需依赖云端服务。mlx-dspark的核心价值在于它充分利用了苹果芯片的硬件特性。DSpark本身是一个高效的推理框架,通过稀疏化和量化技术减少计算开销。移植到苹果的MLX框架后,它能够直接调用Metal Performance Shaders和统一内存架构,从而在MacBook或Mac Studio上实现接近原生性能的推理。对于12B参数的Gemma-4来说,1.6倍的提升意味着在复杂任务如代码生成或文本分析中,响应时间从秒级缩短到毫秒级,极大提升了本地体验。这一进展对AI从业者意义重大。许多开发者日常使用Mac进行模型调优和测试,但受限于本地算力,往往需要转向云端GPU。mlx-dspark的出现打破了这一瓶颈,使得在Mac上运行中等规模的大模型变得切实可行。Qwen3-4B的1.4倍加速虽然看似温和,但考虑到其轻量级设计,这一优化足以让它在低功耗场景下(如笔记本电池模式)保持高效。行业观察人士指出,类似的技术移植可能推动更多开源模型向苹果生态迁移,进一步降低AI开发的门槛。展望未来,mlx-dspark的潜力不止于此。随着DSpark社区的持续迭代,预计后续版本将支持更多模型类型,并针对苹果最新的M4系列芯片进行深度适配。对于Mac用户和AI爱好者,建议立即尝试mlx-dspark,在本地运行Gemma-4或Qwen3,亲身体验速度提升带来的效率变革。同时,关注DSpark的更新动态,以便第一时间获取针对其他模型的优化支持。本地AI的加速竞赛已经开启,而苹果芯片正成为这场竞赛中的一匹黑马。
DeepSeek技术移植苹果芯片,Mac模型生成速度飙升60%
AITNT
4小时前
4
0