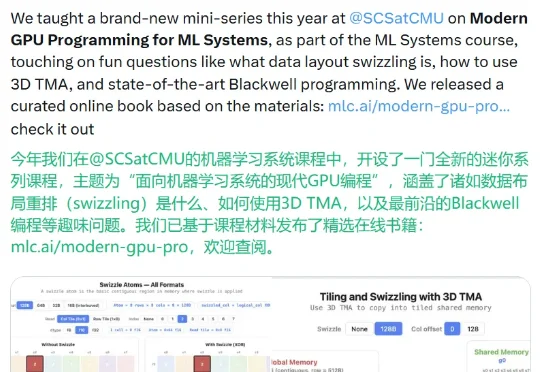
在机器学习系统领域,GPU编程能力正在成为区分普通工程师与高阶系统工程师的关键技能。CMU助理教授、TVM与XGBoost的创造者陈天奇,近日与多位合作者共同推出了免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代GPU编程)》,为这一领域提供了系统化的学习路径。这不仅是技术教程,更是陈天奇团队在MLSys领域多年工程经验的结晶,直接回应了当前AI从业者面对GPU编程时“知其然不知其所以然”的普遍痛点。
全书分为多个递进章节,从GPU架构基础讲起,逐步深入到内存层次结构、计算优化、算子融合、分布式训练等ML系统特有的挑战。与通用GPU编程教材不同,本书特别强调ML工作负载的特性,比如如何为Transformer模型设计高效的Kernel,如何处理大模型训练中的显存碎片化问题。书中提供了大量可运行的代码示例,覆盖CUDA、Triton等主流编程框架,并附带性能对比数据——例如通过优化内存访问模式,可使特定算子的执行速度提升3到5倍。这些内容直接源于陈天奇团队在TVM、MLC-LLM等项目中的实战经验,因此更具工程参考价值。
从行业影响来看,这本书的出现恰逢其时。当前大模型训练和推理对GPU算力的需求呈指数级增长,但能高效利用硬件特性的工程师仍然稀缺。许多AI从业者熟悉PyTorch等高层框架,却在GPU编程层面遇到瓶颈,导致模型部署效率低下、显存浪费严重。陈天奇的新书直接瞄准这一鸿沟,为ML系统工程师提供了一份从入门到进阶的“操作手册”。值得注意的是,本书完全免费且持续更新,这种开放共享的姿态也延续了陈天奇在TVM、XGBoost等开源项目中的一贯精神。
对于想要深入ML系统底层的开发者,这本书是一个不容错过的学习资源。建议读者具备基本的深度学习知识和一定的C++/CUDA基础,阅读时重点关注书中关于内存优化和算子融合的章节,这些是提升GPU利用效率的核心技巧。同时,配合实际动手运行代码示例,效果会比单纯阅读好得多。随着ML系统对硬件效率的要求越来越高,掌握GPU编程将在未来几年成为AI工程师的核心竞争力之一,而陈天奇的这本书正好为你铺好了第一块垫脚石。