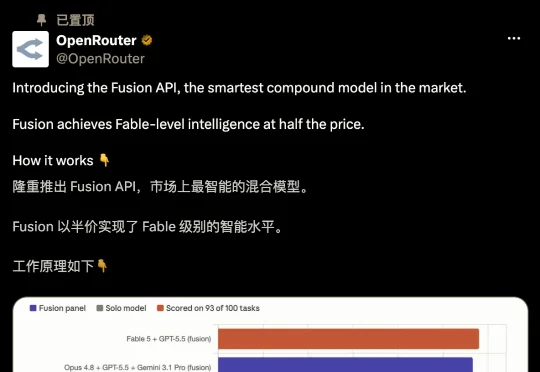
当Anthropic的Claude Fable 5因全球禁用而成为焦点时,OpenRouter悄然上线了一个名为Fusion的功能,其效果令人震撼——几个高性价比的国产开源模型组团协作,竟然能直接打平Fable 5,而价格仅需后者的一半。这不仅是技术上的突破,更是一次关于“智能性价比”的革命:过去我们追逐单模型的绝对上限,现在,组合的力量正在改写规则。
测试采用Perplexity的DRACO基准,覆盖学术、金融、法律等10个领域,每道题有约39条带权重的评分标准,答错扣分,杜绝堆字数。OpenRouter公布了三个关键发现:第一,组团稳定优于单跑,融合配置在榜单上整体更高;第二,顶配组团能“超出前沿”,如Fable 5加GPT-5.5的69.0%天花板;第三,预算组(Gemini 3 Flash、Kimi K2.6、DeepSeek V4 Pro)拿到64.7%,干掉了单跑60.0%的GPT-5.5和58.8%的Opus 4.8,距离Fable 5的65.3%仅差不到一个百分点,成本却只有前沿组团的一半。值得注意的是,Fable 5的65.3%只算了93道题,另有7道被其内容过滤器拦截,若补足可能成绩更高,但这恰恰暴露了单模型的软肋——最强的模型也最会拒绝你。
Fusion的核心机制并非简单的投票选优。裁判模型会通读所有回答,生成结构化分析,列出共识、矛盾、独到见解和共同盲区,最后由作答模型基于此重新写稿。这意味着,当一个模型掉链子时,其他模型能顶上。对用户而言,使用Fusion极其简单:在API调用中填入模型名openrouter/fusion即可,或将其作为工具挂入tools列表,甚至可在网页版openrouter.ai/fusion选择预设套餐或自建面板。
这一变化对开源模型是实打实的利好。预算组中的Kimi K2.6和DeepSeek V4 Pro均来自国产开源路线,单拎出来未必跑得过闭源前沿,但组团后差距被大幅缩小。当低价能换来几乎一样高的智能,“单模型最强”这个指标的分量就被稀释了,性价比从次要变量跃升为主角。对走性价比路线的国内模型公司来说,Fusion开辟了新赛道:不必在单模型刷榜上与闭源巨头硬碰,靠组合也能交付接近前沿的结果。开源模型,可能要迎来第二春了。