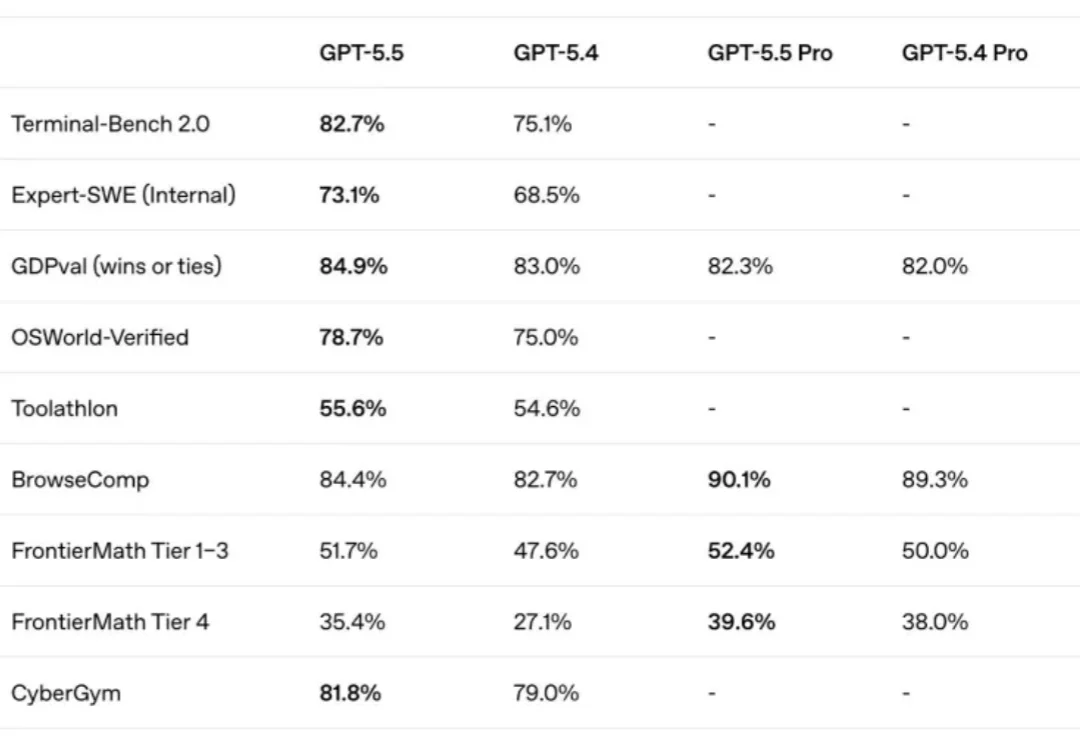
当大模型在复杂推理、自动化研究和网络安全等高难度任务中展现出越来越强的能力时,我们用来衡量它们的尺子,却可能已经悄悄落伍了。OpenAI研究员Noam Brown近日撰文指出,传统模型评测方式正面临根本性挑战:模型的表现不仅取决于其本身,更取决于它在推理阶段获得了多少计算资源。这一观点,正在引发AI行业对评测体系的深层反思。长期以来,模型发布总伴随着一张由多项基准测试构成的成绩表:数学、编程、科学问答等能力被压缩为若干分数,供人横向比较。但Brown以GPT-5.5的发布为例,揭示了这种方式的局限性。在GPT-5.5上线初期,外界首先注意到一组并不算特别显眼的基准测试成绩,与GPT-5.4相比提升幅度有限,部分用户因此持观望态度。然而,随着开发者开始测试更复杂的任务,一些用户发现GPT-5.5在长链条推理、持续执行和复杂问题处理方面表现出明显的代际差异。这种实际体验显著增强、榜单分数却变化有限的现象,反映出传统评测没有完整呈现模型能力。问题在于,不同模型的评测结果未必建立在相同的推理预算之上,某些模型在获得更多推理token或更长运行时间后能继续显著提升,而另一些则较早触及上限。Brown展示的网络安全评测案例进一步说明了这一点。如果只比较各模型在所谓最大测试时计算量条件下的最终成绩,GPT-5.5相较GPT-5.4的优势可能并不突出。但如果将token数量、推理成本或延迟控制在相同水平,再观察不同模型的表现,GPT-5.5的能力提升会更加明显。换言之,模型间的差距不仅体现在最终分数上,也体现在利用额外推理计算量的效率上。对于新一代模型而言,性能平台期可能远比预期更晚出现,甚至在现实可承受的预算范围内难以观测。Brown引用了Andrej Karpathy的自动化研究实验,其中模型持续执行大量试验后,性能仍保持改善趋势。英国人工智能安全研究所的评测也显示,包括部分模型在内,在累计使用超过1亿token后,任务表现仍然继续提高。面对这一变化,Brown建议行业从单点成绩转向性能—推理计算量曲线。模型发布机构应在横轴上标注推理计算量,纵轴上展示任务表现,绘制完整的性能变化曲线,横轴可以采用token数量、推理费用或实际运行时间等指标。这种方法能够回答传统成绩表难以解释的问题:在相同预算下,哪个模型表现更好?当预算增加十倍时,哪个模型提升更快?目前,ARC-AGI等评测已开始尝试衡量模型分数与运行成本之间的关系。对于AI从业者而言,这意味着在评估模型时,不应只看榜单上的一个数字,而要关注其在不同推理预算下的表现曲线,以及成本效益的变化趋势。这不仅是技术评测的进化,更是AI安全政策和实际部署决策中必须纳入的基础变量。