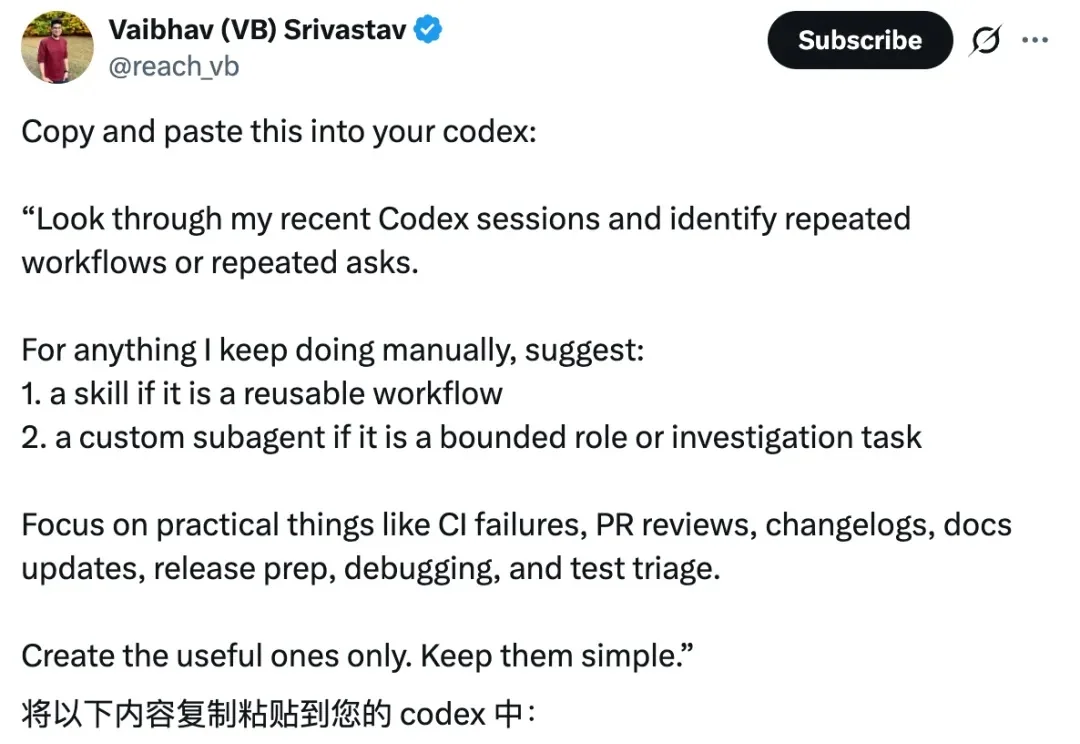
OpenAI员工Vabihav(简称VB)近日在社交媒体上公开了Codex自我蒸馏的秘诀,引发开发者社区热议。只需将一段提示词复制粘贴进Codex,AI就能自动翻查历史会话,找出用户反复手动执行的重复工作流,并将其打包成可复用的工具。OpenAI总裁Greg Brockman亲自转发点赞,并顺带提醒:Codex是开源的。
VB发布了两个版本的提示词。第一版仅9行,聚焦CI失败、PR审查、changelog等程序员常见任务,建议将重复流程创建为Skill,将边界明确的角色或调查任务设为Custom Subagent。但评论区反馈该提示词过于专业,非程序员用户难以应用。VB随即在当天推出第二版,提示词扩展至35行,数据源从“最近会话”升级到Memories和Chronicle(4月20日上线的屏幕截取预览功能),覆盖范围从编码任务扩展到写作、规划、沟通、运营等全场景。输出方式也从“给建议”升级为“直接创建”,高置信度条目由AI自动生成Skill、Subagent或Automation,低置信度或一次性任务则跳过。
该方法的实用性获得不少网友认可,但token消耗问题成为关注焦点。有网友质疑回看30天历史记录会消耗大量token,VB未正面回应,但提到OpenAI近期在重置Codex的速率限制。另有用户发现,自动生成的Skill中约有一半来自“输入未稳定时就做过两次的事”,维护这些抽象的成本可能高于直接重做。这引发了关于AI自主判断与人工把关平衡的讨论。目前Chronicle仅对macOS上的ChatGPT Pro订阅用户开放,记忆未加密存储在本地,会快速消耗速率限制。
对于AI从业者而言,这一技巧展示了如何利用Codex的自我蒸馏能力提升工作效率,但需注意token成本和抽象维护的风险。建议先从高频、稳定输入的工作流入手,逐步探索最适合的自动化形式。随着Codex持续迭代,这种“让AI教会AI”的模式或将成为未来工作流优化的新范式。