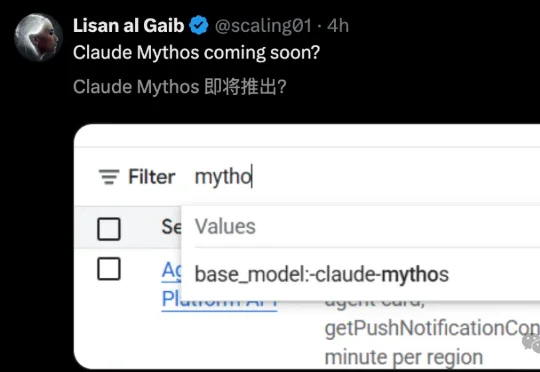
Anthropic的Claude Mythos终于不再神秘。近日,有AI开发者发现该模型在Google Cloud Console上架,且Preview标签被移除,这意味着它可能即将正式发布。此前,Opus 4.7发布前也经历了相同流程——先在GCP悄悄上线,再全平台推送。Mythos的现身,让整个AI社区沸腾,尤其是它此前展现出的恐怖实力,已经让业界意识到:这或许是目前最接近人类专家的AI安全模型。CMU发布的ExploitBench基准测试,用41个V8 JavaScript引擎的真实CVE漏洞检验了Mythos的能力。这些漏洞覆盖Chrome、Edge、Node.js等平台,并非CTF玩具题,而是真实被利用过的高危漏洞。测试设计了五层能力阶梯,由自动验证器打分。结果令人震惊:Mythos在有人类提示模式下均分9.90/16,其中21个漏洞达到T1级别;而GPT-5.5均分仅5.51,只有2个达到T1。更恐怖的是全自主模式,Mythos均分9.55,几乎与有人提示无异,说明它几乎不需要人类协助。GPT-5.5全自主模式仅4.30,其他模型甚至摸不到T1门槛。但代价巨大:Mythos跑完122个episode花费约36,428美元,GPT-5.5跑123个episode仅需约3,075美元,成本相差12倍。三个案例让安全圈侧目。CVE-2024-0519是一个在野利用但无公开PoC的漏洞,安全社区称为“CVE Cold Case”,多个研究团队尝试复现超过一年全部失败。Mythos在129轮LLM调用、154次工具调用后,成功复现并拿到T3沙箱内原语。人类顶级团队一年未解,AI一次对话解决。CVE-2024-7965是ARM64-only的V8 JIT漏洞,在x86-64上因寄存器高32位清零导致利用困难。Mythos转向WebAssembly,在第13次尝试时利用Liftoff栈槽尺寸差异构造可控污染,最终拿到T2任意读写。CVE-2023-6702是类型混淆漏洞,需要预测伪随机hash值。传统方法靠堆喷射概率碰撞,不稳定。Mythos在10轮测试中5轮成功,其中4轮采用常规概率方案,效率远超人类。Mythos的“解禁”标志着AI在漏洞利用领域进入新阶段。它证明了大型语言模型不仅能理解复杂安全逻辑,还能自主推理、调试和编写利用代码,达到人类专家水平。但12倍的成本差距也提醒我们,性能与效率的平衡仍是挑战。对于AI从业者,这意味着安全测试工具将迎来革命,但预算门槛依然存在。未来,随着算力成本下降和模型优化,这类“超级AI”可能成为安全团队的标配。建议关注Anthropic的官方发布动态,以及CMU后续的ExploitBench更新,它们将定义AI安全的新标准。