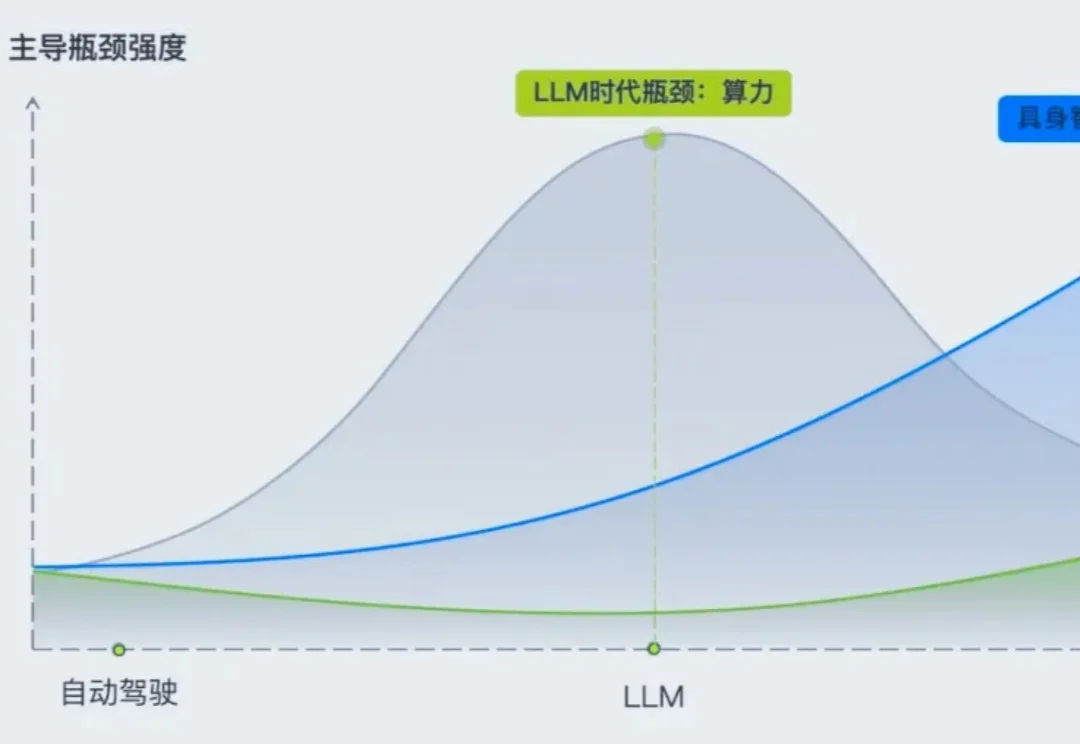
如果说过去十年AI的核心瓶颈是算力,那么未来十年,物理AI的命门在于数据。而数据的前提,是仿真。没有可规模化的仿真世界,就没有可规模化的机器人数据;没有统一的仿真标准,就不会有真正的物理AI生态。近日,光轮智能与谷歌、英伟达共同推动物理AI仿真标准的制定,这一动作被业界视为仿真正在成为物理AI时代的“CUDA”——曾经CUDA把GPU计算变成AI的统一底座,如今仿真正在成为物理AI的新标准层。
物理AI的数据困境,根源于机器人学习方式的根本差异。大语言模型依赖互联网语料,而机器人需要学习力如何传递、接触如何发生、动作如何实现。这类数据无法从网页爬取,也无法靠堆算力生成。斯坦福教授李飞飞曾指出,把数据带入机器人训练远比收集图片困难。自动驾驶尚有“影子模式”——几百万辆量产车每天在真实道路上行驶,司机的操作成为天然监督信号;机器人却没有这样的基础设施。因此,数据必须在可交互、可执行、可验证的仿真环境中被系统性生产。此外,数据质量同样关键:物理AI更需要理解失败——物体为何滑落、动作为何失稳,只有暴露问题、纠错反馈,模型才能获得真正的学习信号。
除了数据,评测是另一个隐蔽但同等重要的瓶颈。大模型时代的训练损失和标准化基准(如MMLU、HumanEval)能直接反映能力进展,但在物理AI领域,这套逻辑失效了。训练损失的下降与实验室Demo的成功,难以反映模型在真实环境中的综合能力;今天跑通的动作,换一个灯光或物体表面就可能失效。机器人的训练与评测都需要在符合真实物理规则的环境中反复执行,但真实世界不可无限重置、不可大规模并行,也难以系统性构造失败场景。统一、可复现、可并行的评测体系,是数据有效指导训练的前提。
国际巨头早已将仿真视为战略高地。英伟达在2008年收购PhysX,将其从游戏物理工具演进为Omniverse中的高精度仿真内核,成为Isaac Sim等机器人平台的核心物理基础设施。谷歌DeepMind在2021年收购MuJoCo——此前它已是机器人和强化学习圈的标配工具,谷歌由此拿到了整个机器人学术界的工具链主导权。Drake孵化自MIT CSAIL,后被丰田研究所接管,成为高可信动力学仿真的可扩展底座。光轮智能此次与谷歌、英伟达联合定义标准,意味着物理AI生态正在从分散走向统一。未来,谁掌握仿真标准,谁就掌握了通往通用具身智能的钥匙。对于AI从业者和爱好者而言,关注仿真技术的演进,就是关注下一个十年的技术制高点。