{
title: "云知声U2-ASR 2.5发布,方言转写准确率突破96%",
summary: "云知声推出首个中文方言语义转写大模型U2-ASR 2.5,覆盖七大方言体系,支持100种以上方言及口音识别,方言人口覆盖率超90%。在工业级测试中,济南话准确率达96.2%,四川话94.7%,粤语93.0%。模型不仅实现方言到普通话的转写,更引入语义还原能力,让AI真正听懂方言。通用中英文测试中,AISHELL-1达99.2%,Libri Clean达98.4%,展现了扎实的语音识别底座。",
content: "方言识别,一直是语音AI领域公认的硬骨头。不同地区的口音差异、方普混说、同音异形词,让传统ASR模型常常束手无策。今天,云知声正式推出U2-ASR 2.5,这是业内首个专注中文方言语义转写的大模型,标志着AI从‘听清’走向‘听懂’的关键一步。基于山海·知音2.0的升级,U2-ASR 2.5全面覆盖七大方言体系,支持100种以上方言及地方口音,方言人口覆盖率高达90%以上,直接回应了真实世界中复杂多样的语音需求。
在技术实现上,U2-ASR 2.5围绕数据、解码与语义理解三条链路进行了系统性优化。数据层面,构建了‘真实数据收集+公开语料补充+半监督扩增+人工校准’的闭环,通过VAD、降噪、去重等处理提升数据纯度,并利用语音合成与数据增强扩大样本规模。解码层面,引入语种边界预测模块和动态语种注意力机制,能实时处理方言、普通话、英语的词级穿插,在混合语境中保持稳定识别。最关键的是语义层升级,模型通过方言词义映射、上下文意图识别与多源知识融合,将晦涩、口语化的方言表达转化为规范、准确的普通话文本,实现了从语音识别到语音理解的跃迁。
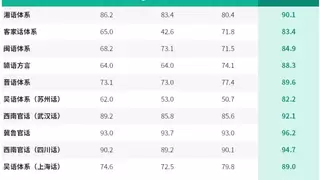
评测数据证明了这一突破的含金量。在工业级方言测试集上,济南话识别准确率高达96.2%,四川话94.7%,粤语93.0%,武汉话92.1%,全面超越主流ASR模型。同时,在通用中英文公开测试集中,AISHELL-1达到99.2%,Libri Clean达到98.4%,AISHELL-3达到98.4%。这表明U2-ASR 2.5并非在通用能力之上简单叠加方言识别,而是在扎实的语音底座上向高难场景拓展,兼顾了广度和精度。
对于AI从业者而言,U2-ASR 2.5的发布意味着方言场景的落地门槛正在降低。无论是智能客服、语音助手,还是会议转写、内容审核,方言识别能力的提升将直接改善用户体验。未来,随着更多地域语料的积累和语义理解的深化,方言AI有望从‘能识别’走向‘稳识别’,在真实业务中发挥更大价值。建议关注该模型在智能家居、车载语音、医疗问诊等场景的应用进展,这或许是下一波语音交互革新的关键变量。"
}