事情是酱的。
这天我在AA榜上看前28的模型感到有点陌生。
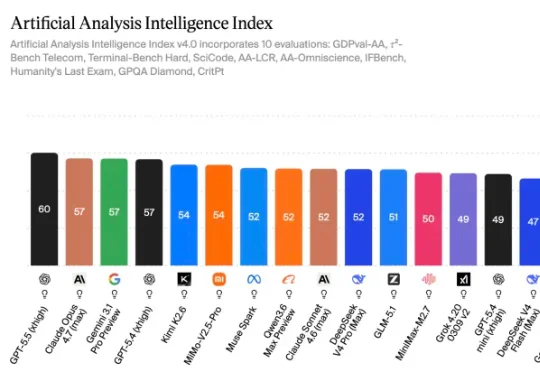
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,
记忆一样,skill一样,系统设置一样,能调用的工具也一样。
我只换模型。
这次的4个候选是GPT 5.5、MiniMax M2.7、DeepSeek V4 Pro和小米Mimo-V2.5-Pro,默认能开高推理就上高。
为什么没上Opus?
API太费钱,账号额度不敢打满,比起作为Agent的主力还要长时间不掉线的模型,它还是更适合养在web端上,至少我这样Claude Design能爽用。
那我们先用30s简单回顾一下这次横测的选手们!
DeepSeek V4 Pro最近还刚开了识图模式,5月底之前都是2.5折。V4 Pro的总参数量1.6T,比V3.2翻了两倍多。
这四个模型的API价和订阅价我都放在后面用表格对比了,所以我们先看后续。V4 Pro这几天有被发现放在Agent场景上识别本地的Skill不成功,执行高风险动作的时候也没有询问的,用人话说就是Agent框架失效了。
还有说V4 Pro巨烧token的,同样的任务是sonnet 4.6 medium的8倍。
我太好奇了我。
Mimo-V2.5-Pro也传很猛,能跟和GLM 5.1打得有来有回。但额度也烧超快,据说是一个5分钟编程任务月额度就没了50%。
我更好奇了我。
所以才有了这次的四个模型搭配,选MiniMax M2.7是因为它的Codng Plan真的量大管饱。这段时间MiniMax开源了自家CLI,在一个coding plan里还用视频生成,音乐生成和语音合成模型,不需要额外去接MCP server,额度也是分开计算的。
长话短说,
我这次设计了5个Agent任务,但不想写成机械的case1、case2、case3。那太像实验报告,读起来也没劲。
你可以把它理解成5关,包括Skill打包,网页开发,PPT设计和文案,知识库管理和巨烧token的浏览器自动化。
Here we go!
第一关,
让模型把Claude Design提示语打包成可发布的skill。这一步是文档整理的升级版,Hermes自己也会时不时被动触发新建Skill,如果说一个模型连稳定把我们的经验打包成Skill都做不到的话,下面救不用测了。
把我提供给你Claude Design提示语(/Users/carl/Downloads/Claude-Design-Sys-Prompt.txt)整理成一个可线上发布的skill。
目标不是复制提示语,而是把它封装成别人装上就能用的能力包。
输出后自检一次,指出这个skill可能出错的地方。
PS:模型他们用到的Hermes是完全复刻了我本地已经用了几个月的原型,所以并不会出现说一些专有名词完全不懂,或者是一些约束完全不知道的情况。
实际上手就会很明显发现就算记忆备份一样,不同模型说话的风格就是很不同。
GPT 5.5列出了它在原版提示语提到的一些能力,然后去掉了一些很明显的约束条件,因为这些放到别的模型或者别的环境的时候不会起作用,然后也为了线上发布,在这个skill上做了这个命名规避,整体来说就是一个很标准的答案。
MiniMax 2.7在打包的过程发现了更多的细节,包括因为它只是一个提示语,里面提到的很多环境都是没有的,所以直接打包成Skill的时候,会把这些理想化的条件设定进去。
2.7还觉得现在Skill的触发条件不够宽。现有的触发只给了设计关键词,但是如果我说给我做一个好看的页面的时候,是不会触发的。
发现这个Skill有缺陷的时候,比方说JS或者是动画组件不完整。他也给了我对应的解决方案,要不要去联网搜索来去补足。所以这个skill后续的完整性我觉得是会更好。
DeepSeek V4 Pro同样是自检出了不少的问题。
我觉得给我的一个惊喜就是不像开头听到的,Agent框架的约束不起作用,至少在这个case上也没有明显体验到,甚至是提出了一些我在之前用Claude Opus 4.6打包这个skill的时候,我没看到的一些潜在的问题,
所以我也很好奇,后面让他用自己打包好的skill做网站设计的时候,表现会是怎么样的。
小米这个就跟其他三家都不太一样了。
他先是看到我本地已经有一个打包好的 Claude design skill,他觉得这个skill已经非常完善了,去检查了一下它有没有什么问题。
当我明确给他答复,我们要打包成为一个新的skill之后,他又给了我打包了个新的,自检结果大家也可以看出来不一样了。他更多的是针对这个skill在触发的过程中,会遇到什么使用问题。
马上到第二关,
基于这个skill做个人网页。
这关测的是审美迁移,很多模型会背Skill里的设计词,但做出来还是公式模板味。
我直接就是把一个简历和公开知识库的链接作为这次的数据源。
加载刚生成的Claude Design风格skill,为卡尔做一个个人网页单页,让陌生人快速理解卡尔的价值。
按照你对卡尔的理解,还有他的简历(/Users/carl/Downloads/2026-04-22__文档_其他__简历(23-03-06).pdf),以及他公开的知识库
(https://aiwarts101.feishu.cn/wiki/MZTNwQ7b9i1dyXklFxzcirOxnRg?fromScene=spaceOverview)。
卡尔想要一个交互超级不一样的页面。
结尾说明你的视觉决策。
PS:每个都配了飞书Cli,所以他们读取的知识库是有快100个表格和文档的。
GPT 5.5,
我只能说学Claude有点有点子学到精髓了。但是也不知道它是怎么去做这个定位跟整个尺寸的放大缩小了,可以看到它那个页面跟它里面的这些组件不是说完全对位的,整体是往左边上面缩小的。
虽然说它有一个比较有意思的互动,包括中间的SVG点击可以跳转不同的页面,以及右下角的这个一个提问,可以问问题给出答案,
但是整体来说我只能说,在大家都只有一次修改的机会上, GPT 5.5这不能说是一个成品。
MiniMax M2.7优先保留了页面的完整性,然后再去做整体的设计和互动。
而且它的互动也是有巧思在里面的。我是程序员,所以它给我保留了这个输入光标,然后用一些动态图表去做成果展示,底部也留下了我的联系方式。
我觉得一个比较难得的细节就是它的中英文字体搭配不丑,很多模型要么就是中英文混杂会很奇怪,要么就是只擅长做一种语言,纯中文或者纯英文,然后再用i18n切换。
DeepSeek这脑回路跟大家想的都不一样,他根据了我们知识库过去分享的一些内容,想出了用鼠标作为探照灯,然后去看四个角跟中间的一部分,我有一些什么样的信息。
比较可惜的就是中间那一页被知识库的信息所污染了。这里面的信息居然全都是Hermes和OpenClaw的一些特点。所以我只能说交互方式我觉得还蛮惊喜的,跟V3.2还是有比较不一样的,但在这个长文知识处理上,比我想象中差点。
小米的话,网页就更贴合普通的个人网站了,
在第四页做
千元横测GPT、DeepSeek、Xiaomi、MiniMax的最强模型,我找到了跟Agent们的绝配
AITNT
29天前
3
0
本文由 Zyentor(智元界) 原创发布,转载请注明出处。
欢迎在 技术论坛 讨论本文相关内容