导读
【导读】NVIDIA Dynamo 团队发现,Claude Code 向自定义端点发送请求时,prompt 最前面会带一行 session-specific billing header。这行 header 每个 session 都变,导致 52K token 的稳定前缀在 KV cache 中无法复用——TTFT 从 168ms 飙到 912ms。Dynamo 加了一个 --strip-anthropic-preamble flag,TTFT 立刻回到 169ms,快了将近 5 倍。
模型没换,GPU 没换,TTFT 差了 5 倍
同一个模型,同一块 B200,同一段 52K token 的 prompt。
NVIDIA Dynamo 的测试结果:
KV cache 正常命中时,TTFT
168ms
保留一行 session-specific billing header,TTFT
912ms
用 --strip-anthropic-preamble 去掉 header,TTFT
169ms
差异来自一行字。代价是
744ms/请求
。
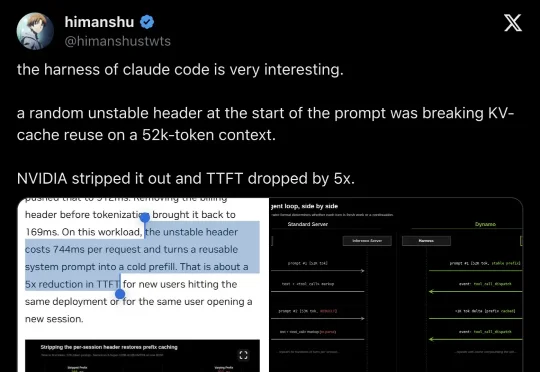
开发者 himanshu 在 X 上分享了这个发现,原话是:
"a random unstable header at the start of the prompt was breaking KV-cache reuse on a 52k-token context. NVIDIA stripped it out and TTFT dropped by 5x."
「prompt 开头的一个不稳定 header 破坏了 52K 上下文的 KV-cache 复用。NVIDIA 把它去掉后,TTFT 降了 5 倍。」
▲ himanshu 在 X 上分享 Claude Code KV-cache 问题,附 NVIDIA 文档截图
但要理解这 5 倍差距从哪来,得回到 NVIDIA 的官方文档。
▲ NVIDIA 文档 TTFT 对比图:Stable Prefix 168ms、Varying Prefix 911ms、Stripped Prefix 169ms,标注 5x faster
这行 header 长什么样
NVIDIA Dynamo 文档给出了示例:
text x-anthropic-billing-header: cc_version=0.2.93; cch=abc123def456==; You are Claude Code, an interactive CLI tool...
x-anthropic-billing-header 出现在 prompt 最前面,token 序列的第 0 位附近。每个 session 的值都不一样——版本号、billing 标识都在变。
关键在于:
KV-cache 的 prefix 匹配从第一个 token 开始,逐 token 比对。
只要第 0 位的 token 变了,后面即使有 52K token 完全相同的 system prompt、tool definitions、对话历史,prefix cache 都不会命中。全部从头算。
NVIDIA 文档用了一个词:
poison
。
"These headers poison the KV cache and prevent it from being reused... A varying line at position zero means every new session starts from a different token prefix..."
「这些 header 会『污染』KV cache 并阻止复用……第 0 位的一行变化,意味着每个新 session 都从不同的 token prefix 开始。」
一次 cold prefill 就要把 52K token 全部重新计算。168ms 变成 912ms 就是这么来的。
▲ NVIDIA Dynamo 文档 "Prompt Stability Is Key for Cache Reuse" 段落,含 billing header 示例和 KV-cache 失效机制
为什么 coding agent 对此特别敏感
普通聊天可能就几轮对话。Coding agent 完全不同。
NVIDIA Technical Blog 的描述:
"Tools like Claude Code and Codex make hundreds of API calls per coding session, each carrying the full conversation history."
「Claude Code 和 Codex 一次编码会话可能发起数百次 API call,每次都携带完整对话历史。」
数百次请求,每次都拖着不断增长的上下文。KV-cache 复用在这种场景下收益巨大:
首次 API call 写入 KV cache 后,后续请求在同一 worker 上可以命中
85–97%
cache
4 个 Opus teammates 的 agent swarm 可以达到
97.2%
aggregate cache hit rate
11.7x
的 read/write ratio——系统写一次 cache,读近 12 次
典型的 write-once-read-many 模式。Cache 命中时效率极高,但只要 prefix 匹配失败,所有优势瞬间归零。
▲ NVIDIA Technical Blog:Full-Stack Optimizations for Agentic Inference with NVIDIA Dynamo
修复方案:在 tokenization 前把 header 剥掉
Dynamo 的方案就一步——在 tokenization 之前移除不稳定 header:
"remove the unstable billing header before tokenization so that the stable prompt starts at token zero."
「在 tokenization 前移除不稳定 billing header,让稳定 prompt 从 token zero 开始。」
具体操作是在 Dynamo 启动配置中加上 --strip-anthropic-preamble,和 --enable-anthropic-api、--enable-streaming-tool-dispatch 配合使用。
不改模型、不改 GPU 配置、不改 prompt 内容。只在请求进入 tokenizer 之前做一次字符串处理。TTFT 从 912ms 回到 169ms。
这算 bug 还是设计选择?
社区对此有不同看法。
X 上 @drummatick 的观点:
"technically it's not a harness issue"
他认为这个 billing header 可能是 Anthropic 有意放在
Claude Code 每条请求暗藏一行「有毒」header,52K 上下文推理被拖慢 5 倍!NVIDIA 一个 flag 修好了
AITNT
2026-05-11
29
0