刚刚,DeepSeek融资这件事差不多落定了。
据top华人科创社区消息,此轮由阿里、腾讯和国家大基金各注资 100 亿,加上创始人梁文锋个人的 200 亿组成,公司估值约为 3500 亿人民币。
为稳住团队,DeepSeek 目前的薪酬已经翻倍,核心研究员期权达到 8 位数。
除了融资上的事情备受关注,DeepSeek 还有一个非常值得聊的事情。
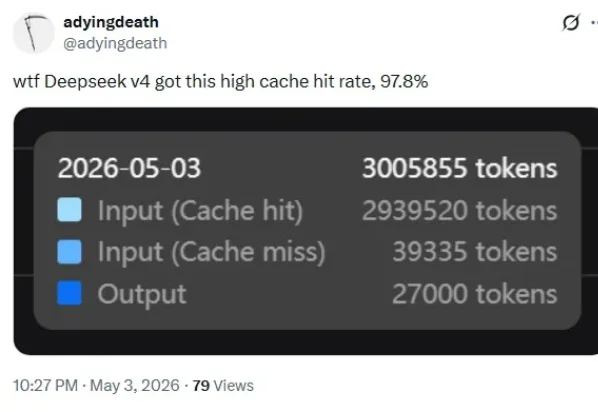
API 越用越便宜,缓存命中率高达 98%!
随便打开论坛,都会看到开发者在晒 DeepSeek 的 API 账单,配文都差不多
:「这缓存命中率是不是有点太高了?」
这命中概率,太离谱了。
而且官方还特意在文档里表示,缓存命中的概率「不是百分之百」。
去看看它的定价表,就知道这事有多离谱。
DeepSeek-v4-flash,输入Token 没命中缓存的时候收你 1 元/百万。命中缓存了呢,0.02元/百万,直接砍到五十分之一。
v4-pro当前还在 2.5折活动中,未命中3元/百万,命中缓存0.025元/百万,两者差了120倍。
也就是说,大部分用户在使用DeepseekV4时,账单上的数字小得让人有点眩晕。
所以,DeepSeek,你到底怎么做到的?
我们今天就来聊聊这事。
一、能存进硬盘
在聊这件事之前,得先把「缓存」这件事本身讲清楚。
很多朋友虽然在用,可能都不知道它到底是个啥。
想象你在读一本很厚的小说,边读边在笔记本上记:「这一章谁出场了、谁跟谁闹翻了、主线推进到哪一步了。」
第二天朋友突然问你:「主人公的舅舅最后死了吗?」
你不用把整本书从头翻一遍,直接翻笔记本,几秒钟就能答上来。 这种“现成答案直接调用”的情况,就叫「缓存命中」。
放到大模型上,逻辑一模一样。只不过那本“笔记本”里记的不是剧情梗概,而是模型读你输入的文本时,在脑子里算出来的中间状态,学名叫 KV Cache。
假设你手上有一本5万字的超长小说,你要上传给 AI,然后对它反复提问。
没有
KV Cache
的情况是:你上传小说,问「这本书的主人公是谁?」AI 逐字逐句啃完5万字,理解内容,好不容易算出答案,耗时巨长。
然后你接着问「他最后结婚了吗?」
AI很绝望,因为它得再从头啃一遍5万字,才能回答你第二个问题。
每一个新问题都得重复一次酷刑。
有
KV Cache
的情况完全不一样。你上传完小说后,AI就会把对这部小说的理解笔记存到了草稿纸上。
你接着问第二个问题,AI会先检查草稿纸,只花几秒扫一眼你的新问题,瞬间给出答案。
传统的Transformer模型用的是
MHA架构
,它们在「思考」每一段内容的时候,都会生成一张巨大的
KV Cache。
这张
KV Cache
有多大?大模型场景下动辄几GB 甚至几十GB。这么大的东西,只能在GPU显存里放着,因为显存的读写带宽可以达到每秒3TB,而固态硬盘只有每秒 7GB,差了400多倍。
而DeepSeek用的是独特的MLA架构,V4之后更是进一步升级,采用CSA+HCA架构,由压缩稀疏注意力CSA和重度压缩注意力HCA构成,极致压缩token数量,同时又捕获重要且必不可少的信息。
MLA相对于传统MHA就提升显著,更别说V4之后的技术了。两者的区别可以说是一个天上,一个地下,为了方便,我换个生活化的方式给你来解释。
想象一个人正在复习,他的大脑相当于GPU显存,处理速度飞快,但容量有限;而他的书包相当于硬盘,容量大,但翻找起来慢得多。
传统
MHA架构
,像这个人有强迫症,必须在巨大纸上密密麻麻写下每一个要点,才能继续往下复习。这张纸太大了,大到除了占用你仅有的桌面(显存),哪儿都放不下。
由于显存又贵又有限,这张大纸很快会占满,如果他还想往下复习,只能扔掉旧的纸。下一道题哪怕有重复内容,也得重新写一遍。
MLA
则不一样,他没有强迫症,也不用写满整张大纸,而是把同样的内容浓缩成一张小索引卡,体积压缩到原来的十分之一以上。
索引卡可以放桌面(显存),依然可以处理当下的问题;但更关键的是,复习的知识终于可以塞进书包(硬盘)了,不用直接扔了。
桌面只能放 10 张卡,书包能放几千上万张,容量是成百上千倍的差距。
今天上午做的所有题,都还在书包里,下午再遇到类似题目,直接从书包里掏出来就能继续。而V4升级后的CSA+HCA架构更为复杂,篇幅原因就不过多展开了,放一张图网上找到的总结图:
极致压缩技术,让庞大的 KV Cache变得足够「苗条」,从而第一次就能被放进成本极低的硬盘仓库中,长期保存和调用。
正是因为能放在硬盘里了,系统才敢放心地把你几小时甚至几天前的对话都缓存下来。
二、存得久,还不够
但光存得久还不够。
你存的东西,得能在下一次请求来的时候精确地对应上,这样才不会出现偏差。
于是,语言模型的「完整回传」设计,起到了作用。
每一次,DeepSeek写入硬盘的缓存,都是基于「你的原话 + 完整的思考过程 + 最终回复」这整个序列生成的。
也就是说,它在便利贴上写的索引,是整个一长条的问答。
等你追问新的问题时,你表面上只输入了几个字。但你的Deepseek在背后发送的请求,并不是简单的一句话。
而是第一轮问题 + DeepSeek的完整思考过程 + 上一轮的最终回复 + 你新加的「问题」。
上一轮的整段思考过程,就完整地嵌在你的请求里,作为「前缀」被送回来了。
然后 DeepSeek 拿这个请求,跟硬盘上的缓存索引做比对。因为开头完全一致,所以你第一轮的所有计算都可以跳过,算力只用来处理你新加的请求。
这样,整个对话就达到了闭环。
「完整回传」是所有 Chat Completion API 的通用做法(OpenAI、Anthropic、Google 都一样,API 本身是无状态的)。
「前缀」缓存命中也是所有主流推理引擎(vLLM、SGLang 等)的通用能力。
但DeepSeek 的真正优势是,缓存能存得很便宜。
好,读到这里,你可能有一个疑问,硬盘不是比显存慢 400 倍吗,那我用的时候怎么没感觉慢?
你说到点子上了。
硬盘读数据确实比显存慢,但DeepSeek的工程团队做了一件很聪明的事,他们把那点延迟藏在了你本来就有的等待时间里。
你的请求从设备出发,经过路由器,到达服务器,这个过程本身就要花50到100毫秒。在这段时间里,服务器并不是干等着。
它同时跑了两条线。一条线往硬盘发出缓存读取指令,另一条线开始解析协议、分配GPU资源。
等网络传输结束、GPU 资源就绪的时候,硬盘那边的缓存数据也已经到位了。
而且,这里的“硬盘”并不是传统机械硬盘,实际用的是企业级固态硬盘(SSD),顺序读取速度能达到每秒7GB。
DeepSeek用到的压缩缓存非常小,读完只需要几十微秒,几乎可以忽略不计。
你问「你好吗」这种短句,有缓存还是没缓存,响应时间都在 0.5 到 0.8 秒之间,
人类根本感知不到差别。
但到了大场景就不一样了。上传一本 5 万字的小说然后反复追问,有缓存的情况下首字延迟还是 0.5 秒左右。
没缓存?5万字全部重新算一遍,10 到 30 秒起步。
所以你真正能感知到的不是它的慢,而是它的快。
长文档追问时那种「秒回」的感受,和极低的API费用,才是你体感里真正记住的东西。
而那一点硬盘读
刚刚,DeepSeek融资差不多落定了,首轮500亿!DeepSeek缓存命中率冲到98%?
AITNT
19天前
5
46
本文由 Zyentor(智元界) 原创发布,转载请注明出处。
欢迎在 技术论坛 讨论本文相关内容