GLM-OCR
简介
👋 Join our WeChat and Discord community 📍 Use GLM-OCR's API 👉 GLM-OCR SDK Recommended 📖 Technical Report
模型卡片
模型配置
模型详情
已翻译GLM-OCR
👋 加入我们的 微信 和 Discord 社区
📍 使用 GLM-OCR 的 API
👉 推荐使用 GLM-OCR SDK
📖 技术报告
简介
GLM-OCR 是一个用于复杂文档理解的多模态 OCR 模型,基于 GLM-V 编码器-解码器架构构建。它引入了多 token 预测(MTP)损失和稳定的全任务强化学习,以提高训练效率、识别准确率和泛化能力。该模型集成了在大规模图像-文本数据上预训练的 CogViT 视觉编码器、具有高效 token 下采样的轻量级跨模态连接器,以及 GLM-0.5B 语言解码器。结合基于 PP-DocLayout-V3 的布局分析和并行识别两阶段流程,GLM-OCR 在各种文档布局上提供了稳健且高质量的 OCR 性能。
主要特性
-
最先进的性能:在 OmniDocBench V1.5 上取得 94.62 分,综合排名第一,并在包括公式识别、表格识别和信息提取在内的主要文档理解基准测试中取得最先进结果。
-
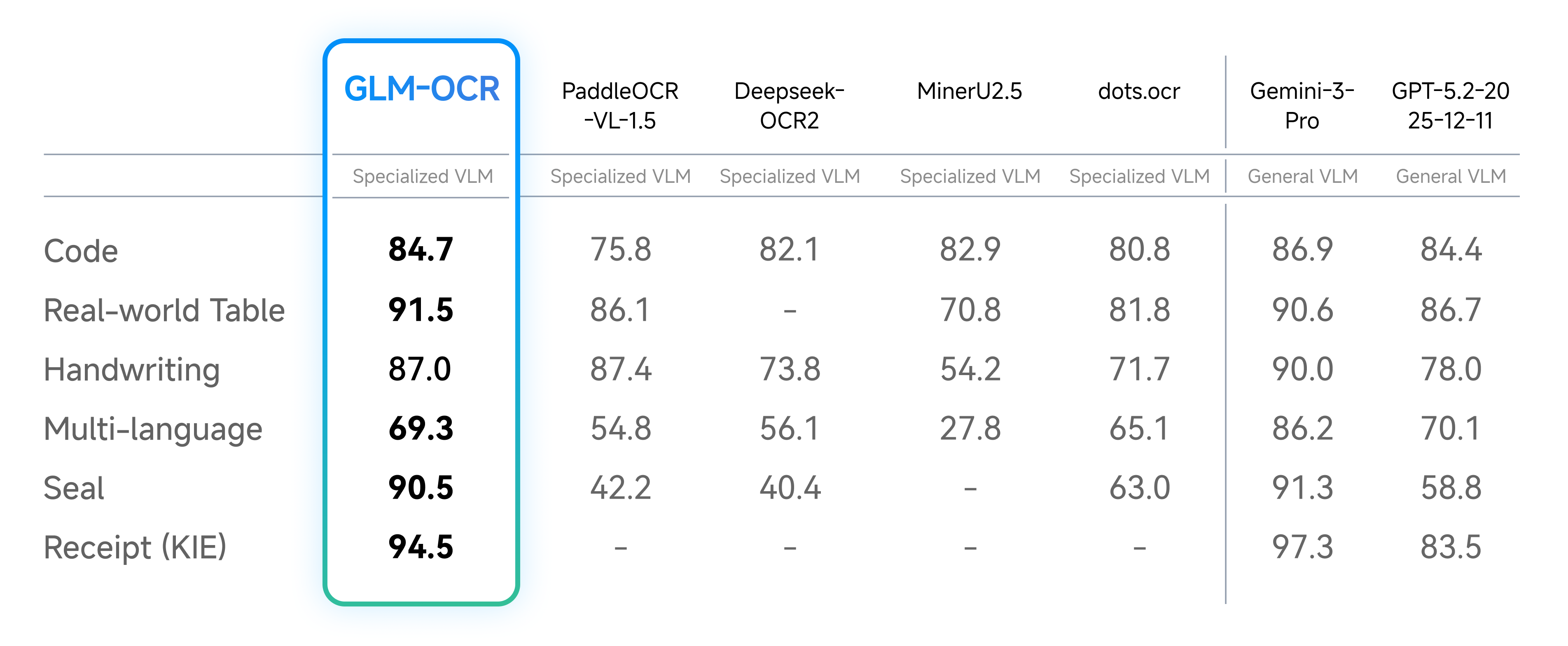
针对真实场景优化:针对实际业务用例设计和优化,在复杂表格、密集代码文档、印章及其他具有挑战性的真实布局上保持稳健性能。
-
高效推理:仅 0.9B 参数,支持通过 vLLM、SGLang 和 Ollama 部署,显著降低推理延迟和计算成本,是高并发服务和边缘部署的理想选择。
-
易于使用:完全开源,配备全面的 SDK 和推理工具链,安装简单、一行调用,可平滑集成到现有生产流程中。
性能
- 文档解析与信息提取
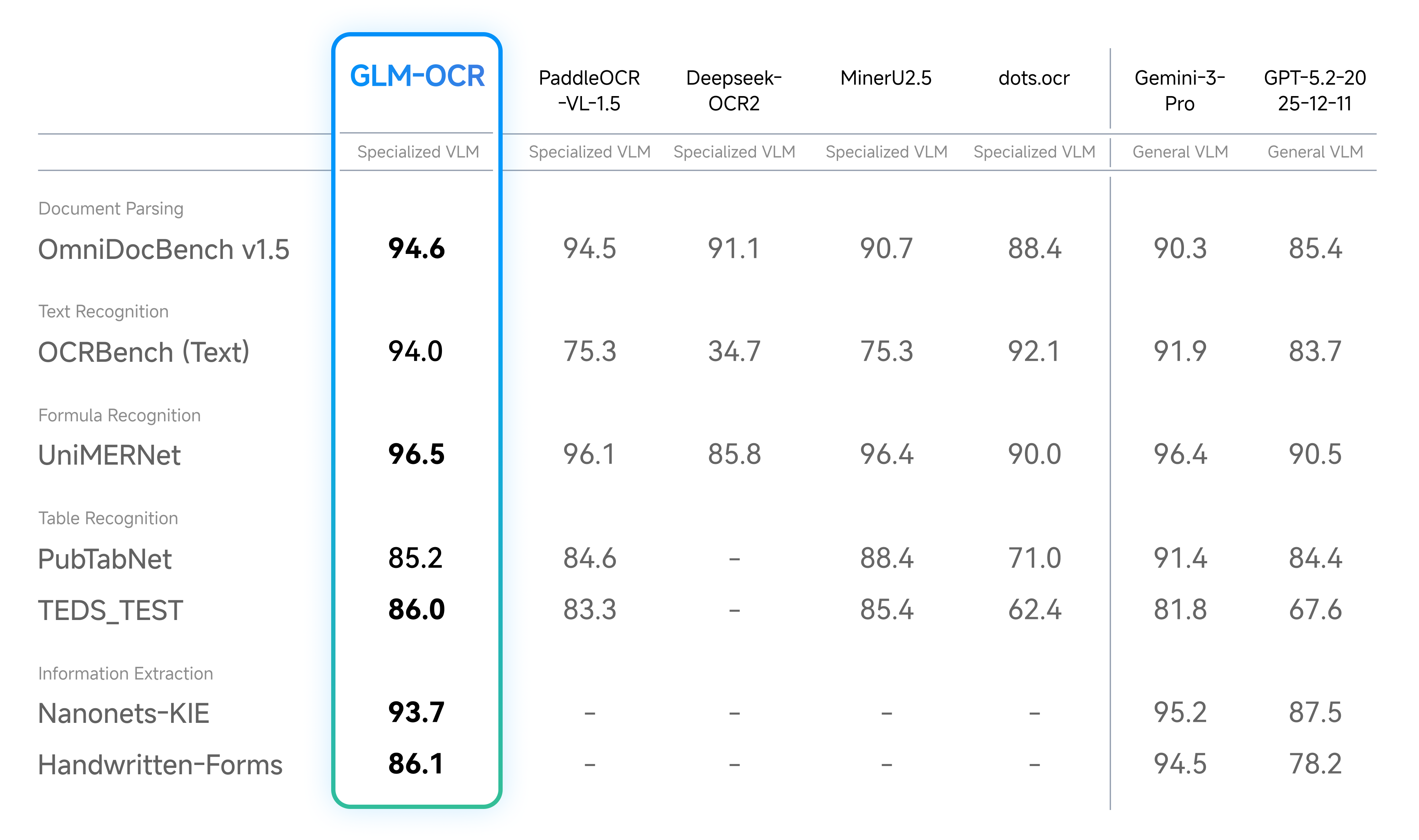
- 真实场景性能
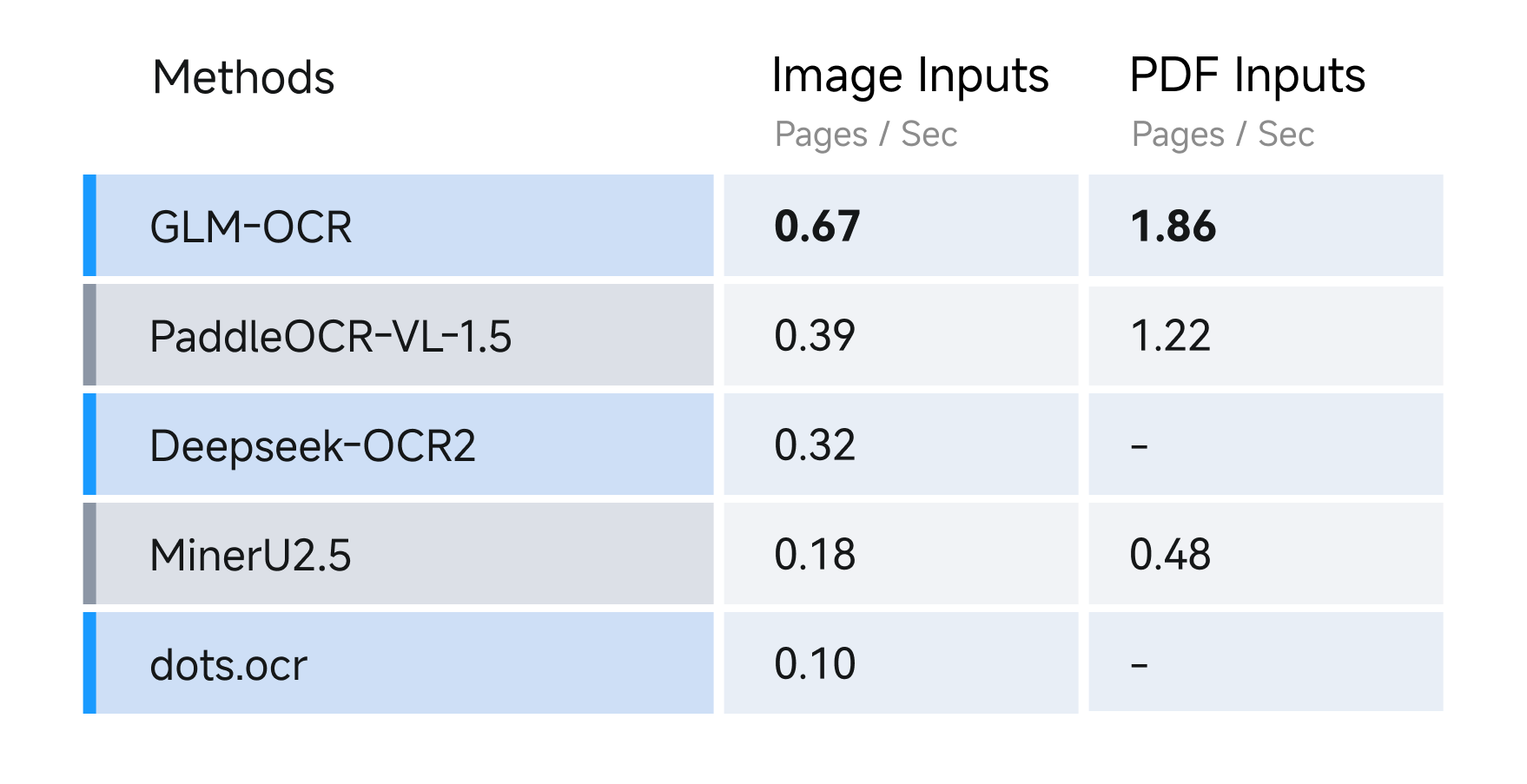
- 速度测试
在速度方面,我们在相同的硬件和测试条件下(单副本、单并发)比较了不同的 OCR 方法,评估它们在从图像和 PDF 输入解析并导出 Markdown 文件时的性能。结果显示,GLM-OCR 对 PDF 文档的吞吐量达到 1.86 页/秒,对图像的吞吐量达到 0.67 图像/秒,显著优于同类模型。
使用方法
官方 SDK
对于文档解析任务,我们强烈推荐使用我们的官方 SDK。
与纯模型推理相比,SDK 集成了 PP-DocLayoutV3,并提供了完整、易用的文档解析流程,包括布局分析和结构化输出生成。这显著降低了构建端到端文档智能系统所需的工程开销。
请注意,SDK 目前仅针对文档解析任务设计。对于信息提取任务,请参考以下部分,直接使用模型进行推理。
vLLM
- 运行
pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly
或使用 Docker:
docker pull vllm/vllm-openai:nightly
- 运行:
pip install git+https://github.com/huggingface/transformers.git
vllm serve zai-org/GLM-OCR --allowed-local-media-path / --port 8080
SGLang
- 使用 Docker:
docker pull lmsysorg/sglang:dev
或从源码构建:
pip install git+https://github.com/sgl-project/sglang.git#subdirectory=python
- 运行:
pip install git+https://github.com/huggingface/transformers.git
python -m sglang.launch_server --model zai-org/GLM-OCR --port 8080
Ollama
- 下载 Ollama。
- 运行:
ollama run glm-ocr
当图像被拖入终端时,Ollama 会自动使用图像文件路径:
ollama run glm-ocr Text Recognition: ./image.png
Transformers
pip install git+https://github.com/huggingface/transformers.git
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
MODEL_PATH = "zai-org/GLM-OCR"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "test_image.png"
},
{
"type": "text",
"text": "Text Recognition:"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = AutoModelForImageTextToText.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto",
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
inputs.pop("token_type_ids", None)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
提示词限制
GLM-OCR 目前支持两种类型的提示词场景:
- 文档解析 – 从文档中提取原始内容。支持的任务包括:
{
"text": "Text Recognition:",
"formula": "Formula Recognition:",
"table": "Table Recognition:"
}
- 信息提取 – 从文档中提取结构化信息。提示词必须遵循严格的 JSON 格式。例如,提取个人身份信息:
请按下列JSON格式输出图中信息:
{
"id_number": "",
"last_name": "",
"first_name": "",
"date_of_birth": "",
"address": {
"street": "",
"city": "",
"state": "",
"zip_code": ""
},
"dates": {
"issue_date": "",
"expiration_date": ""
},
"sex": ""
}
⚠️ 注意:使用信息提取时,输出必须严格遵循定义的 JSON 格式,以确保下游处理的兼容性。
致谢
本项目受到以下优秀项目的启发
正在翻译中,请稍候...
标签
操作
详细信息
- 厂商
- zai-org
- 任务
- image-to-text
- 框架
- transformers
- 模型类型
- glm_ocr
- 许可(HF)
- mit
- 语言
- zh, en, fr, es, ru, de, ja, ko