Qwen3-4B-Instruct-2507
简介
We introduce the updated version of the **Qwen3-4B non-thinking mode**, named **Qwen3-4B-Instruct-2507**, featuring the following key enhancements:
模型卡片
模型配置
模型详情
已翻译Qwen3-4B-Instruct-2507
亮点
我们推出了 Qwen3-4B 非思考模式 的更新版本,命名为 Qwen3-4B-Instruct-2507,具有以下关键增强特性:
- 通用能力显著提升,包括指令遵循、逻辑推理、文本理解、数学、科学、编程和工具使用。
- 多语言长尾知识覆盖大幅增强。
- 在主观和开放式任务中与用户偏好的对齐明显改善,能够提供更有帮助的回复和更高质量的文本生成。
- 256K 长上下文理解能力增强。
模型概述
Qwen3-4B-Instruct-2507 具有以下特点:
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 参数数量:4.0B
- 非 Embedding 参数数量:3.6B
- 层数:36
- 注意力头数(GQA):Q 为 32,KV 为 8
- 上下文长度:原生支持 262,144。
注意:该模型仅支持非思考模式,输出中不会生成 ``` 块。同时,不再需要指定enable_thinking=False`。
更多详情,包括基准评估、硬件要求和推理性能,请参阅我们的 博客、GitHub 和 文档。
性能
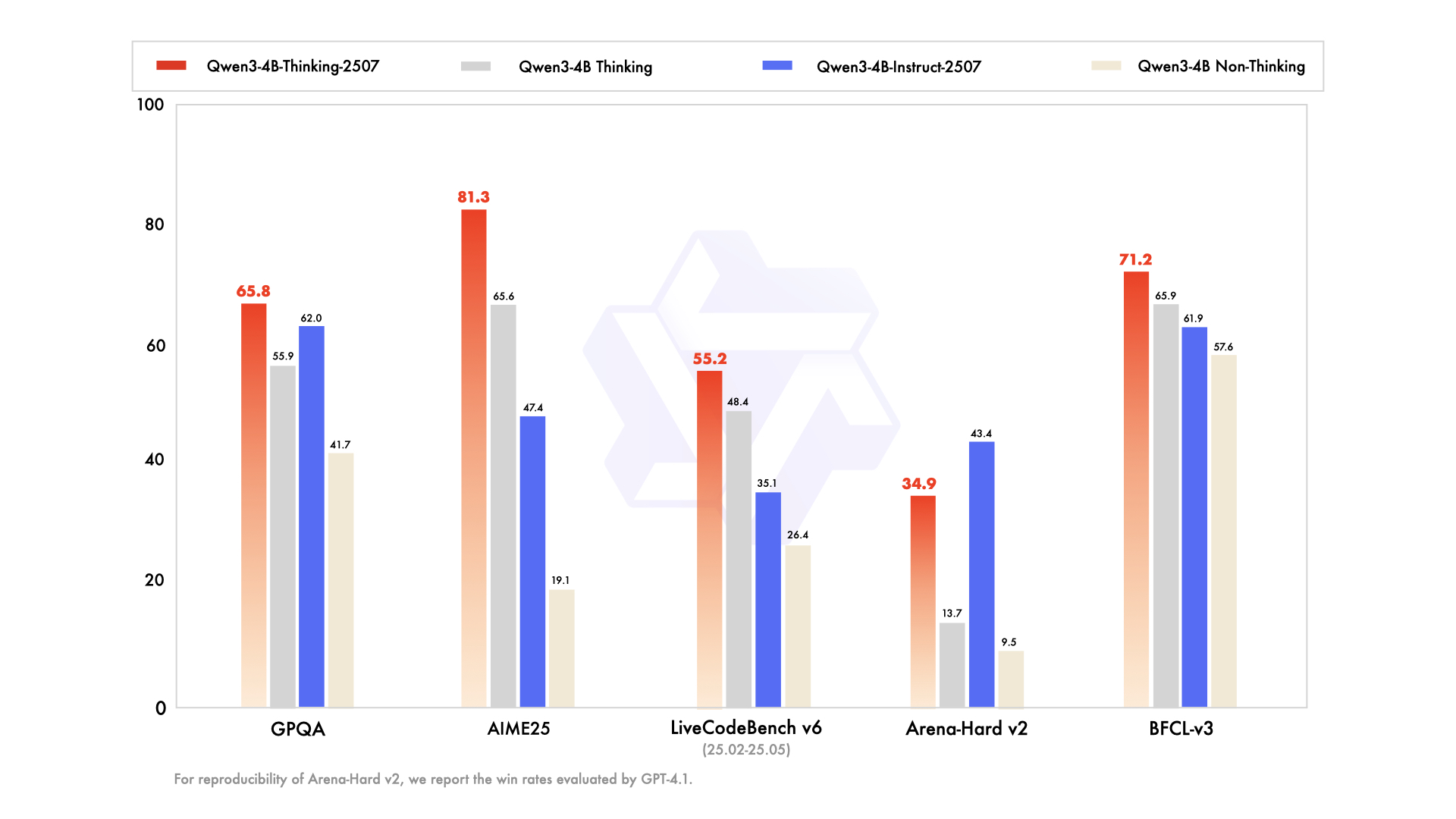
| GPT-4.1-nano-2025-04-14 | Qwen3-30B-A3B 非思考模式 | Qwen3-4B 非思考模式 | Qwen3-4B-Instruct-2507 | |
|---|---|---|---|---|
| 知识 | ||||
| MMLU-Pro | 62.8 | 69.1 | 58.0 | 69.6 |
| MMLU-Redux | 80.2 | 84.1 | 77.3 | 84.2 |
| GPQA | 50.3 | 54.8 | 41.7 | 62.0 |
| SuperGPQA | 32.2 | 42.2 | 32.0 | 42.8 |
| 推理 | ||||
| AIME25 | 22.7 | 21.6 | 19.1 | 47.4 |
| HMMT25 | 9.7 | 12.0 | 12.1 | 31.0 |
| ZebraLogic | 14.8 | 33.2 | 35.2 | 80.2 |
| LiveBench 20241125 | 41.5 | 59.4 | 48.4 | 63.0 |
| 编程 | ||||
| LiveCodeBench v6 (25.02-25.05) | 31.5 | 29.0 | 26.4 | 35.1 |
| MultiPL-E | 76.3 | 74.6 | 66.6 | 76.8 |
| Aider-Polyglot | 9.8 | 24.4 | 13.8 | 12.9 |
| 对齐 | ||||
| IFEval | 74.5 | 83.7 | 81.2 | 83.4 |
| Arena-Hard v2* | 15.9 | 24.8 | 9.5 | 43.4 |
| Creative Writing v3 | 72.7 | 68.1 | 53.6 | 83.5 |
| WritingBench | 66.9 | 72.2 | 68.5 | 83.4 |
| 智能体 | ||||
| BFCL-v3 | 53.0 | 58.6 | 57.6 | 61.9 |
| TAU1-Retail | 23.5 | 38.3 | 24.3 | 48.7 |
| TAU1-Airline | 14.0 | 18.0 | 16.0 | 32.0 |
| TAU2-Retail | - | 31.6 | 28.1 | 40.4 |
| TAU2-Airline | - | 18.0 | 12.0 | 24.0 |
| TAU2-Telecom | - | 18.4 | 17.5 | 13.2 |
| 多语言能力 | ||||
| MultiIF | 60.7 | 70.8 | 61.3 | 69.0 |
| MMLU-ProX | 56.2 | 65.1 | 49.6 | 61.6 |
| INCLUDE | 58.6 | 67.8 | 53.8 | 60.1 |
| PolyMATH | 15.6 | 23.3 | 16.6 | 31.1 |
*:为便于复现,我们报告了由 GPT-4.1 评估的胜率。
快速开始
Qwen3 的代码已集成到最新的 Hugging Face transformers 中,建议您使用最新版本的 transformers。
使用 transformers=0.4.6.post1 或 vllm>=0.8.5 来创建兼容 OpenAI 的 API 端点:
- SGLang:
shell
python -m sglang.launch_server --model-path Qwen/Qwen3-4B-Instruct-2507 --context-length 262144
- vLLM:
shell
vllm serve Qwen/Qwen3-4B-Instruct-2507 --max-model-len 262144
注意:如果遇到内存不足(OOM)问题,请考虑将上下文长度缩短为较小的值,例如 32,768。
对于本地使用,Ollama、LMStudio、MLX-LM、llama.cpp 和 KTransformers 等应用也已支持 Qwen3。
智能体使用
Qwen3 在工具调用能力方面表现出色。我们建议使用 Qwen-Agent 来充分利用 Qwen3 的智能体能力。Qwen-Agent 内部封装了工具调用模板和工具调用解析器,大大降低了编码复杂度。
要定义可用工具,您可以使用 MCP 配置文件、使用 Qwen-Agent 的内置工具,或自行集成其他工具。
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-4B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
最佳实践
为获得最佳性能,我们建议采用以下设置:
- 采样参数:
- 建议使用
Temperature=0.7、TopP=0.8、TopK=20和MinP=0。 - 对于支持的框架,您可以将
presence_penalty参数调整至 0 到 2 之间,以减少无休止的重复。但使用较高的
正在翻译中,请稍候...