nomic-embed-text-v1.5
简介
nomic-embed-text-v1.5:基于套娃表示学习的可伸缩生产级嵌入模型
模型卡片
模型配置
模型详情
已翻译nomic-embed-text-v1.5: 基于 Matryoshka 表示学习的可调整尺寸生产级 Embedding
博客 | 技术报告 | AWS SageMaker | Nomic 平台
激动人心的更新!: nomic-embed-text-v1.5 现已支持多模态!nomic-embed-vision-v1.5 与 nomic-embed-text-v1.5 的 embedding 空间对齐,这意味着任何文本 embedding 都是多模态的!
使用方法
重要提示:文本 prompt 必须包含一个任务指令前缀,用于告知模型当前执行的任务类型。
例如,如果你正在实现一个 RAG 应用,你需要将文档嵌入为 search_document:,将用户查询嵌入为 search_query:。
注意:从 transformers v5.5.0 和 sentence transformers v5.3.0 开始,trust_remote_code=True 将不再是必需的。目前仅纯文本系列支持此特性。
任务指令前缀
search_document
用途:将文本作为文档进行嵌入
此前缀用于将文本作为文档进行嵌入,例如作为 RAG 索引中的文档。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['search_document: TSNE is a dimensionality reduction algorithm created by Laurens van Der Maaten']
embeddings = model.encode(sentences)
print(embeddings)
search_query
用途:将文本作为待回答的问题进行嵌入
此前缀用于将文本作为问题(数据集中的文档可以解答这些问题)进行嵌入,例如作为 RAG 应用需要回答的查询。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['search_query: Who is Laurens van Der Maaten?']
embeddings = model.encode(sentences)
print(embeddings)
clustering
用途:将文本嵌入以便进行聚类分组
此前缀用于将文本嵌入,以便将其分组为聚类、发现共同主题或去除语义重复项。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['clustering: the quick brown fox']
embeddings = model.encode(sentences)
print(embeddings)
classification
用途:将文本嵌入以便进行分类
此前缀用于将文本嵌入为向量,这些向量将作为分类模型的特征使用。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['classification: the quick brown fox']
embeddings = model.encode(sentences)
print(embeddings)
Sentence Transformers
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
matryoshka_dim = 512
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
embeddings = model.encode(sentences, convert_to_tensor=True)
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
Transformers
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5')
model.eval()
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
+ matryoshka_dim = 512
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
+ embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
+ embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
该模型原生支持将序列长度扩展到 2048 token 以上。具体操作如下:
- tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
+ tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', model_max_length=8192)
- model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5')
+ rope_parameters = {"rope_theta": 1000.0, "rope_type": "dynamic", "factor": 2.0}
+ model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', rope_parameters=rope_parameters)
Transformers.js
import { pipeline, layer_norm } from '@huggingface/transformers';
// Create a feature extraction pipeline
const extractor = await pipeline('feature-extraction', 'nomic-ai/nomic-embed-text-v1.5');
// Define sentences
const texts = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?'];
// Compute sentence embeddings
let embeddings = await extractor(texts, { pooling: 'mean' });
console.log(embeddings); // Tensor of shape [2, 768]
const matryoshka_dim = 512;
embeddings = layer_norm(embeddings, [embeddings.dims[1]])
.slice(null, [0, matryoshka_dim])
.normalize(2, -1);
console.log(embeddings.tolist());
Nomic API
使用 Nomic Embed 最简单的方式是通过 Nomic Embedding API。
使用 nomic Python 客户端生成 embedding 非常简单:
from nomic import embed
output = embed.text(
texts=['Nomic Embedding API', '#keepAIOpen'],
model='nomic-embed-text-v1.5',
task_type='search_document',
dimensionality=256,
)
print(output)
更多信息,请参阅 API 参考文档
Infinity
与 Infinity 配合使用。
docker run --gpus all -v $PWD/data:/app/.cache -e HF_TOKEN=$HF_TOKEN -p "7997":"7997" \
michaelf34/infinity:0.0.70 \
v2 --model-id nomic-ai/nomic-embed-text-v1.5 --revision "main" --dtype float16 --batch-size 8 --engine torch --port 7997 --no-bettertransformer
调整维度
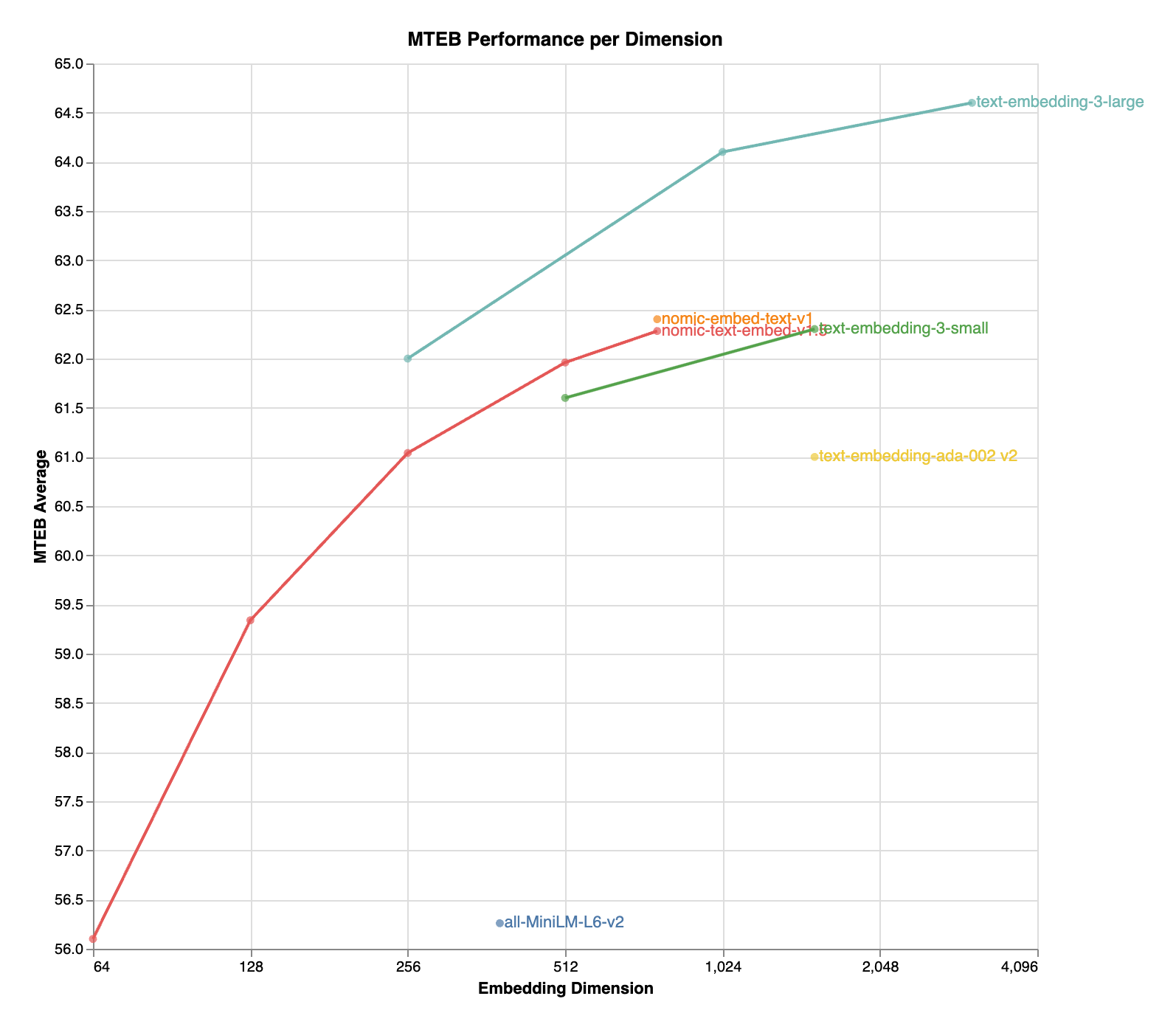
nomic-embed-text-v1.5 是对 Nomic Embed 的改进,采用了 Matryoshka 表示学习 技术,使开发者能够灵活地在 embedding 大小与性能之间进行权衡,且性能损失极小。
| 名称 | 序列长度 | 维度 | MTEB |
|---|---|---|---|
| nomic-embed-text-v1 | 8192 | 768 | 62.39 |
| nomic-embed-text-v1.5 | 8192 | 768 | 62.28 |
| nomic-embed-text-v1.5 | 8192 | 512 | 61.96 |
| nomic-embed-text-v1.5 | 8192 | 256 | 61.04 |
| nomic-embed-text-v1.5 | 8192 | 128 | 59.34 |
| nomic-embed-text-v1.5 | 8192 | 64 | 56.10 |
训练
点击下方的 Nomic Atlas 地图,可视化我们对比预训练数据中的 500 万样本!

我们采用多阶段训练流程来训练 embedding 模型。从长上下文 BERT 模型 开始,第一个无监督对比学习阶段使用弱相关文本对生成的数据集进行训练,例如 StackExchange 和 Quora 等论坛中的问答对、Amazon 评论中的标题-正文对以及新闻文章中的摘要。
在第二个微调阶段,我们利用更高质量的标注数据集,例如网络搜索中的搜索查询和答案。数据筛选和难例挖掘在此阶段至关重要。
更多详情,请参阅 Nomic Embed 技术报告 及相应的 博客文章。
用于训练模型的训练数据已全部发布。更多详情,请参阅 contrastors 仓库
加入 Nomic 社区
- Nomic: [https://nomic.ai](https://no
正在翻译中,请稍候...
标签
操作
详细信息
- 厂商
- nomic-ai
- 任务
- sentence-similarity
- 框架
- sentence-transformers
- 模型类型
- nomic_bert
- 许可(HF)
- apache-2.0
- 语言
- en