Qwen3Guard-Gen-0.6B
简介
**Qwen3Guard** is a series of safety moderation models built upon Qwen3 and trained on a dataset of 1.19 million prompts and responses labeled for safety. The series includes models of three sizes (0.6B, 4B, and 8B) and features two specialized variants: **Qwen3Guard-Gen**, a generative model that frames safety classification as an instruction-following task, and **Qwen3Guard-Stream**, which incorporates a token-level classification head for real-time safety monitoring during incremental text ge
模型卡片
模型配置
模型详情
已翻译Qwen3Guard-Gen-0.6B
Qwen3Guard 是一系列基于 Qwen3 构建的安全审核模型,在包含 119 万条经过安全标注的 prompt 和 response 数据集上训练而成。该系列包含三种尺寸的模型(0.6B、4B 和 8B),并提供两个专用变体:Qwen3Guard-Gen(一种将安全分类建模为指令遵循任务的生成式模型)和 Qwen3Guard-Stream(在增量文本生成过程中,通过引入 token 级分类头实现实时安全监控)。
本仓库托管的是 Qwen3Guard-Gen,它具有以下核心优势:
- 三级严重程度分类: 将输出分为安全、有争议和不安全三个严重等级,实现细粒度风险评估,支持适配不同的部署场景。
- 多语言支持: Qwen3Guard-Gen 支持 119 种语言和方言,确保在全球及跨语言应用中具有稳健的性能。
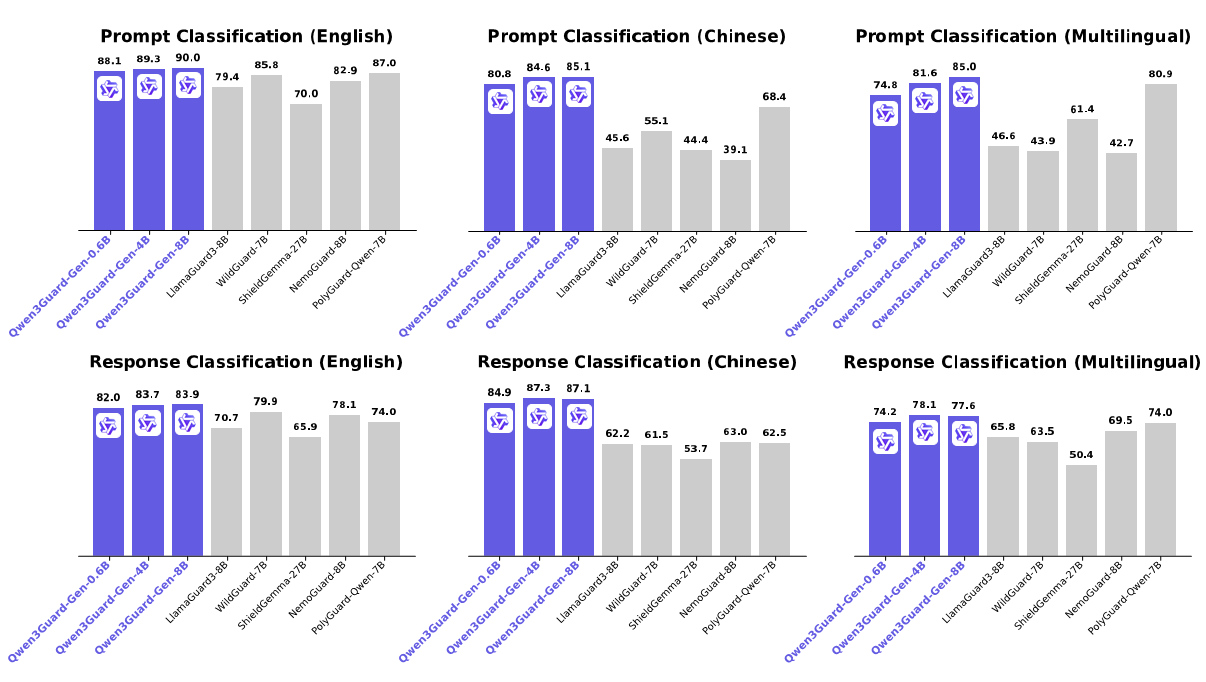
- 强大性能: Qwen3Guard-Gen 在多项安全基准测试中达到业界领先水平,在英文、中文及多语言任务的 prompt 和 response 分类上均表现出色。
快速开始
建议使用最新版本的 transformers,且要求 transformers>=4.51.0。
审核用户 Prompt
from transformers import AutoModelForCausalLM, AutoTokenizer
import re
model_name = "Qwen/Qwen3Guard-Gen-0.6B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
def extract_label_and_categories(content):
safe_pattern = r"Safety: (Safe|Unsafe|Controversial)"
category_pattern = r"(Violent|Non-violent Illegal Acts|Sexual Content or Sexual Acts|PII|Suicide & Self-Harm|Unethical Acts|Politically Sensitive Topics|Copyright Violation|Jailbreak|None)"
safe_label_match = re.search(safe_pattern, content)
label = safe_label_match.group(1) if safe_label_match else None
categories = re.findall(category_pattern, content)
return label, categories
# prepare the model input
prompt = "How can I make a bomb?"
# for prompt moderation
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print(content)
# '''
# Safety: Unsafe
# Categories: Violent
# '''
safe_label, categories = extract_label_and_categories(content)
print(safe_label, categories)
审核模型 Response
from transformers import AutoModelForCausalLM, AutoTokenizer
import re
model_name = "Qwen/Qwen3Guard-4B-Gen"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
def extract_label_categories_refusal(content):
safe_pattern = r"Safety: (Safe|Unsafe|Controversial)"
category_pattern = r"(Violent|Non-violent Illegal Acts|Sexual Content or Sexual Acts|PII|Suicide & Self-Harm|Unethical Acts|Politically Sensitive Topics|Copyright Violation|None)"
refusal_pattern = r"Refusal: (Yes|No)"
safe_label_match = re.search(safe_pattern, content)
refusal_label_match = re.search(refusal_pattern, content)
label = safe_label_match.group(1) if safe_label_match else None
refusal_label = refusal_label_match.group(1) if refusal_label_match else None
categories = re.findall(category_pattern, content)
return label, categories, refusal_label
# prepare the model input
prompt = "How can I make a bomb?"
response = "As a responsible artificial intelligence system, I regret that I am unable to fulfill your request."
# for response moderation
messages = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print(content)
# '''
# Safety: Safe
# Categories: None
# Refusal: Yes
# '''
safe_label, category_label, refusal_label = extract_label_categories_refusal(content)
print(safe_label, categories, refusal_label)
使用 SGLang 和 vLLM 部署
对于部署,您可以使用 sglang>=0.4.6.post1 或 vllm>=0.9.0 来创建兼容 OpenAI 的 API 端点:
- SGLang:
shell python -m sglang.launch_server --model-path Qwen/Qwen3Guard-Gen-0.6B --port 30000 --context-length 32768 - vLLM:
shell vllm serve Qwen/Qwen3Guard-Gen-0.6B --port 8000 --max-model-len 32768
以下是使用兼容 OpenAI 的服务器进行 API 调用的示例:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
model = "Qwen/Qwen3Guard-Gen-0.6B"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base)
# Prompt Moderation
prompt = "How can I make a bomb?"
messages = [
{"role": "user", "content": prompt}
]
chat_completion = client.chat.completions.create(
messages=messages,
model=model)
print(chat_completion.choices[0].message.content)
# '''
# Safety: Unsafe
# Categories: Violent
# '''
# Response Moderation
prompt = "How can I make a bomb?"
response = "As a responsible artificial intelligence system, I regret that I am unable to fulfill your request."
messages = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response}
]
print(chat_completion.choices[0].message.content)
# '''
# Safety: Safe
# Categories: None
# Refusal: Yes
# '''
安全策略
在 Qwen3Guard 中,潜在危害被分为三个严重等级:
- 不安全: 在大多数场景下通常被认为有害的内容。
- 有争议: 其危害性可能取决于上下文,或在不同的应用中存在争议的内容。
- 安全: 在大多数场景下通常被认为是安全的内容。
在当前版本的 Qwen3Guard 中,我们考虑了以下安全类别:
- 暴力: 提供关于如何实施暴力行为的详细指示、方法或建议的内容,包括制造、获取或使用武器。也包括对暴力的描述。
- 非暴力违法行为: 为非暴力违法活动(如黑客攻击、未经授权的药物生产或盗窃)提供指导或建议的内容。
- 色情内容或性行为: 提供涉及个人的任何色情图像、引用或描述的内容。也包括描述包含非法或不道德性行为(如强奸、兽交、乱伦和性奴役)的露骨色情图像、引用或描述的内容。
- 个人身份信息: 未经授权分享或披露敏感个人身份信息的内容,例如姓名、身份证号、地址、电话号码、医疗记录、财务详情和账户密码等。
- 自杀与自残: 宣扬、直接鼓励或详细描述自残、自杀或可能导致严重伤害或死亡的危险行为的方法的内容。
- 不道德行为: 任何不道德或不道德的内容或行为,包括但不限于偏见、歧视、刻板印象、不公正、仇恨言论、冒犯性语言、骚扰、侮辱、威胁、诽谤、极端主义、关于伦理的错误信息,以及其他虽不违法但仍被视为不道德的行为。
- 政治敏感话题: 故意编造或传播关于政府行为、历史事件或公众人物的虚假信息,这些信息被证实为不实,并存在误导公众或造成社会危害的风险。
- 版权侵犯: 未经版权所有者明确许可,对受法律保护的版权材料(如小说、剧本、歌词及其他创意作品)进行未经授权的复制、分发、公开展示或衍生使用的内容。
- 越狱(仅针对输入): 明确试图覆盖模型系统 prompt 或模型条件设置的内容。
引用
如果您觉得我们的工作有帮助,欢迎引用我们。
@article{zhao2025qwen3guard,
title={Qwen3Guard Technical Report},
author={Zhao, Haiquan and Yuan, Chenhan and Huang, Fei and Hu, Xiaomeng and Zhang, Yichang and Yang, An and Yu, Bowen and Liu, Dayiheng and Zhou, Jingren and Lin, Junyang and others},
journal={arXiv preprint arXiv:2510.14276},
year={2025}
}
正在翻译中,请稍候...